In this blog post, I’ll analyze the architecture of Apache Kudu based on the paper Kudu: Storage for Fast Analytics on Fast Data.
Whenever relevant, I’ll compare the architecture design against known architectures and Big Data technologies. Since I’m more Apache Cassandra-biased, most of the time the comparison will be done of course against Cassandra.
All the text in block quote are just excerpts from the Apache Kudu paper. Every thing else is my comments.
I The abstract
I have highlighted relevant keywords in the abstract of the paper.
Kudu is an open source storage engine for structured data which supports low-latency random access together with efficient analytical access patterns. Kudu distributes data using horizontal partitioning and replicates each partition using Raft consensus, providing low mean-time-to-recovery and low tail latencies. Kudu is designed within the context of the Hadoop ecosystem and supports many modes of access via tools such as Cloudera Impala[20], Apache Spark[28], and MapReduce[17]
As always, we need to decode those keywords and their implications:
- structured data: → Apache Kudu will not be a schemaless storage system. Schemaless has been a hype a few years ago but on the long run it becomes less and less relevant
- low-latency random access: → fast random access by primary key(s), not only full sequential scan
- efficient analytical access patterns: → optimized full scan for retrieving massive amount of data
- horizontal partitioning: → some sharding technique is required, either hash-based sharding or functional/column-based sharding or a mix of both
- Raft consensus: → every time you hear Raft, Paxos or Zab (ZooKeeper), you are in front of a system offering some sort of distributed consensus primitive(s)
- Hadoop ecosystem: → strong bias toward master/slave architecture.
That’s a lot to be deduced from the abstract, worry not, we’re going to deep dive very soon into the details.
II Why Apache Kudu ?
In the Hadoop eco-system, there is already a bunch of components/technologies, why yet-another storage engine ? What are the new things does Apache Kudu bring to the table ?
… data formats such as Apache Avro[1] or Apache Parquet[3]. However, neither HDFS nor these formats has any provision for updating individual records, or for efficient random access. Mutable data sets are typically stored in semi-structured stores such as Apache HBase[2] or Apache Cassandra [21]
So the paper acknowledges the fact that existing Hadoop structured storage like HDFS or Apache Parquet fall short on the requirements of fast individual record updates and random access.
However, there is an inaccurate statement about Apache Cassandra. It is not a semi-structured stores. Since the introduction of CQL (version 3) back in 2013 (the paper is written in 2015), Cassandra has a strong schema, unless you use the old and soon-deprecated Thrift API.
Kudu is a new storage system designed and implemented from the ground up to fill this gap between high-throughput sequential-access storage systems such as HDFS[27] and low latency random-access systems such as HBase or Cassandra
So Apache Kudu has been designed to provide fast sequential data access as well as low latency single record random access to the data.
Since there is no silver bullet in life and every architecture choice is a question of trade-off, the alert readers should understand that Apache Kudu will not be as fast as Apache Cassandra for random access and neither as fast as Apache Parquet for pure sequential workload. Rather it’s a conscious choice to offer those 2 conflicting objectives by relaxing the pure performance side.
III High level description
A. Schema
From the perspective of a user, Kudu is a storage system for tables of structured data. A Kudu cluster may have any number of tables, each of which has a well-defined schema consisting of a finite number of columns
The design choice for the data store is, as expected, a strong schema system.
Each such column has a name, type (e.g INT32 or STRING) and optional nullability
Interesting enough, Apache Kudu offers the possibility to declare a column nullable. This implies that there is a control on inserted values at runtime.
Some ordered subset of those columns are specified to be the table’s primary key. The primary key enforces a uniqueness constraint (at most one row may have a given primary key tuple) and acts as the sole index by which rows may be efficiently updated or deleted
The definition of primary key is pretty standard. The fact that Apache Kudu offers uniqueness constraint implies necessarily a read-before-write (e.g. checking for existence of the row before inserting it). This check can be done directly on the data files or via an index structure like Bloom Filter for performance reasons.
This data model is familiar to users of relational databases, but differs from many other distributed datastores such as Cassandra. MongoDB[6], Riak[8], BigTable[12], etc.
Again, the writers of this paper is very unaware about Apache Cassandra because CQL version 3 has been introduced in late 2012 in CASSANDRA-3761
Attempts to insert data into undefined columns result in errors, as do violations of the primary key uniqueness constraint. The user may at any time issue an alter table command to add or drop columns, with the restriction that primary key columns cannot be dropped
The design choice about ALTER TABLE with regard to normal and primary key columns is almost identical to what exist in Apache Cassandra CQL.
B. Writes
After creating a table, the user mutates the table using Insert, Update, and Delete APIs. In all cases, the user must fully specify a primary key – predicate-based deletions or updates must be handled by a higher-level access mechanism (see section 5).
Accessing the rows for mutation should be based on primary key (primary index). Predicate-based mutation should use other higher-level access mechanism → understand a secondary indexing system
Currently, Kudu does not offer any multi-row transactional APIs: each mutation conceptually executes as its own transaction, despite being automatically batched with other mutations for better performance
Apache Kudu does not allow multi-partition transactions, despite having Raft as a consensus protocol. The reason is quite simple. As many master/slave – multi-master distributed systems, the data are distributed across different shards. Each shard has its own primary (understand master) replica + slave replicas.
Allowing multi-partition transactions means that there should be a consensus protocol or a distributed lock that spans across shards. Even if it is technically feasible with Raft, the performance penalty would be very high.
Modifications within a single row are always executed atomically across columns.
Pretty similar to what happens with Apache Cassandra. Indeed all mutations that occur in a single partitions can be guaranteed to be atomic since the mutations only impact a single shard. Providing atomicity in a single shard means providing atomicity of updates on the primary/master replica, no real technical challenge here.
C. Reads
Currently, we offer only two types of predicates: comparisons between a column and a constant value, and composite primary key ranges
- comparisons between a column and a constant value: leveraging columnar indices to fetch the right portions of matching rows
- composite primary key ranges: classical access by primary key ranges (see later for more details)
In addition to applying predicates, the user may specify a projection for a scan. A projection consists of a subset of columns to be retrieved
We are at the core of the columnar storage format. It works best when only a couple of columns are retrieved. Indeed such storage engine is not optimized for SELECT * FROM
D. Consistency
Here we are, this part is extremely important to understand, every word counts!
Kudu provides clients the choice between two consistency modes. The default consistency mode is snapshot consistency. A scan is guaranteed to yield a snapshot with no anomalies in which causality would be violated[1]. As such, it also guarantees read-your-writes consistency from a single client
1: In the current beta release of Kudu, this consistency support is not yet fully implemented. However, this paper describes the architecture and design of the system, despite the presence of some known consistency-related bugs.
First, the paper mentions snapshot consistency. By searching Google, there is nothing such as snapshot consistency. The closest notion would be snapshot isolation. According to the Highly Available Transactions: Virtues and Limitations paper, providing snapshot isolation will forfeit hight availability. I quote an extract of this paper:
5.2.1 Unachievable ACID Isolation
In this section, we demonstrate that preventing Lost Update and Write Skew—and therefore providing Snapshot Isolation, Repeatable Read, and one-copy serializability—inherently requires foregoing high availability guarantees
Next, the paper claims that such snapshot consistency will necessarily guarantee read-your-writes consistency (equivalent to QUORUM in Cassandra) from a single client, which is pretty obvious since the former has stronger requirements than the latter.
Please notice the small [1] footnote. At the time the paper was written the snapshot isolation is not fully implemented because of some known consistency-related bugs. Who said distributed systems is hard ?
By default, Kudu does not provide an external consistency guarantee.
External consistency is also known as strong consistency for transactions or linearizable isolation. Those guarantees are very hard to achieve and has a huge cost on performance.
However, for users who require a stronger guarantee, Kudu offers the option to manually propagate timestamps between clients
Ok but we all know that time is not reliable in distributed system (time-drift occurs all the time). In addition, if you rely on the client for the timestamps, you just move the burden of synchronizing server clocks to the client-side …
If propagating tokens is too complex, Kudu optionally uses commit-wait as in Spanner[14]. After performing a write with commit-wait enabled, the client may be delayed for a period of time to ensure that any later write will be causally ordered correctly. Absent specialized time-keeping hardware, this can introduce significant latencies in writes (100-1000ms with default NTP configurations), so we anticipate that a minority of users will take advantage of this option
Really interesting details here. The alternative to synchronizing client clock is to use the commit-wait protocol inspired by Spanner. But since no one can afford atomic clocks synchronized by GPS systems in his data centers, the latencies cost is dramatic. But at least the users have the choice. Trade-off as always.
The assignment of operation timestamps is based on a clock algorithm termed HybridTime[15]. Please refer to the cited article for details.
Without going into the detail of HybridTime algorithm and research paper, what you should know is that all clients choosing this algorithm for consistency on writes must make sure that the timestamp that is received from the server is propagated to other servers and/or clients. Which is a rather strong requirement in a system where you may have hundreds of servers and maybe more clients.
Although Kudu uses timestamps internally to implement concurrency control, Kudu does not allow the user to manually set the timestamp of a write operation
This restriction is understandable and logic when Apache Kudu uses the HybridTime algorithm for its consistency management.
We do, however, allow the user to specify a timestamp for a read operation. This allows the user to perform point-intime queries in the past
This feature is quite interesting, it means that Apache Kudu should keep some kind of history for each row and column ?
IV Architecture
A. Cluster role
Kudu relies on a single Master server, responsible for metadata, and an arbitrary number of Tablet Servers, responsible for data
We have a master/slave architecture here. At least it’s clearly said, not like some other technologies which claims to have a shared-nothing architecture but which indeed are using a multi-master model. (The general rule of thumb is whenever you see the shared-nothing architecture keyword, try to dig into the architecture. You may have 90% of chance to face a multi-master technology)
The master server can be replicated for fault tolerance, supporting very fast failover of all responsibilities in the event of an outage
I love this sentence, that’s what I used to call the wrong rhetoric objection.
The problem is not how fast the cluster can fail over a master node to transfer responsibilities to another node in case of failure of the former. No, the real problem is how long it takes to detect that the master node is down …

Domain of Unavailability
B. Partitioning
As in most distributed database systems, tables in Kudu are horizontally partitioned. Kudu, like BigTable, calls these horizontal partitions tablets. Any row may be mapped to exactly one tablet based on the value of its primary key, thus ensuring that random access operations such as inserts or updates affect only a single tablet
For Apache Cassandra veterans, tablets ~ token ranges
For large tables where throughput is important, we recommend on the order of 10-100 tablets per machine. Each tablet can be tens of gigabytes.
So for high throughput, maximum recommendation is 100 tablets per machine, and each tablet can be ~10Gb big, which give us max ~1Tb worth of data per machine. This is the maximum density per node, not very impressive for compared to pure analytics dedicated technologies where node density can be 10Tb or more.
Unlike BigTable, which offers only key-range-based partitioning, and unlike Cassandra, which is nearly always deployed with hash-based partitioning, Kudu supports a flexible array of partitioning schemes
It’s true that the Apache Cassandra community strongly recommends using hash-based partitioners (RandomPartitioner or Murmur3Partitioner) and avoid at all cost the old ByteOrderPartitioner because of potential hotspots. Apache Kudu claims to have flexible partitioning schemes, what is this magic ??? Be patient!
The partition schema acts as a function which can map from a primary key tuple into a binary partition key. Each tablet covers a contiguous range of these partition keys. Thus, a client, when performing a read or write, can easily determine which tablet should hold the given key and route the request accordingly
This description fits exactly the definition of token ranges in Apache Cassandra. Good ideas get re-used, no surprise.
The partition schema is made up of zero or more hash partitioning rules followed by an optional range-partitioning rule:
- A hash-partitioning rule consists of a subset of the primary key columns and a number of buckets. For example, as expressed in our SQL dialect, DISTRIBUTE BY HASH(hostname, ts) INTO 16 BUCKETS. These rules convert tuples into binary keys by first concatenating the values of the specified columns, and then computing the hash code of the resulting string modulo the requested number of buckets. This resulting bucket number is encoded as a 32-bit big-endian integer in the resulting partition key
- A range-partitioning rule consists of an ordered subset of the primary key columns. This rule maps tuples into binary strings by concatenating the values of the specified columns using an order-preserving encoding
For anyone familiar with Apache Cassandra, Apache Kudu hash partitioning rule ~ partition key columns (for data distribution) and range-partitioning rule ~ clustering columns (for sorting and range scans).
Users always specify rows, partition split points, and key ranges using structured row objects or SQL tuple syntax. Although this flexibility in partitioning is relatively unique in the “NoSQL” space, it should be quite familiar to users and administrators of analytic MPP database management systems.
Seriously the authors of Apache Kudu paper did not follow at all the evolution of Apache Cassandra CQL (version 3). The notion of partition keys and clustering columns have been introduced 2 years prior to the paper publication date. It looks like the authors only knows the old Thrift API (and even with this old API, you already have the notion of (composite) partition keys and composite column names!!!!)
C. Replication
When creating a table, the user specifies a replication factor, typically 3 or 5, depending on the application’s availability SLAs. Kudu’s master strives to ensure that the requested number of replicas are maintained at all times (see Section 3.4.2).
The first sentence just show similarities between Apache Kudu and Apache Cassandra with regard to replication factor. The second sentence is more curious. It sounds like in the face of one data server failure, Kudu will try to replicate the data to another data server to restore the replication factor. We’ll see later all the practical implications of such design choice.
Kudu employs the Raft[25] consensus algorithm to replicate its tablets. In particular, Kudu uses Raft to agree upon each tablet. When a client wishes to perform a write, it first locates the leader replica (see Section 3.4.3) and sends a Write RPC to this replica.
Indeed, it seems to have one Raft leader/master for each tablet (~ Apache Cassandra token range). The role of the Raft leader, as specified in Raft paper, is to reach consensus on all Raft followers. Please note that this Raft leader is different from the Master server mentioned earlier in the paper, the later is dedicated to metadata and cluster topology change.
If the client’s information was stale and the replica is no longer the leader, it rejects the request, causing the client to invalidate and refresh its metadata cache and resend the request to the new leader. If the replica is in fact still acting as the leader, it employs a local lock manager to serialize the operation against other concurrent operations, picks an MVCC timestamp, and proposes the operation via Raft to its followers. If a majority of replicas accept the write and log it to their own local write-ahead logs[2], the write is considered durably replicated and thus can be committed on all replicas.
[2]: Kudu gives administrators the option of considering a write-ahead log entry committed either after it has been written to the operating system buffer cache, or only after an explicit fsync operation has been performed. The latter provides durability even in the event of a full datacenter outage, but decreases write performance substantially on spinning hard disks.
So there we learn that there is a local lock manager to serialize operations in the face of concurrent updates. In Apache Cassandra, within the class AtomicBTreePartition we also have similar pessimistic locking.
Using Raft consensus, the updates are agreed on a majority of replicas, which is pretty equivalent to Apache Cassandra QUORUM consistency with a dedicated coordinator for each token range (which is quite different from pure Apache Cassandra QUORUM where any-node can be coordinator).
Please notice the small [2] note. Again flushing updates to write-ahead log (WAL) is not as obvious as it seems because you face the OS filesystem cache. You have the choice either to completely rely on the OS filesystem buffer but then you don’t have no absolute durability or you can force an fsync call on every flush at the expense of latency. Similarly in Apache Cassandra you can configure the property commitlog_sync in cassandra.yaml to either batch or periodic for the desired outcome.
If the leader itself fails, the Raft algorithm quickly elects a new leader. By default, Kudu uses a 500-millisecond heartbeat interval and a 1500-millisecond election timeout; thus, after a leader fails, a new leader is typically elected within a few seconds.
Ok so we’re at the heart of the unavailability domain I mentioned earlier. The paper says 500-millisecond heartbeat interval but does not specify how many heartbeats are required before declaring a Raft leader dead.
The devil is in the details:
- if 1 single heartbeat is used to declared a leader dead, then we can have over-failover e.g. as long as the leader does not answer to a heartbeat for whichever reason (network packet lost, OS heavy load …) the cluster switch Raft leader. In an overloaded cluster, this can lead to cascading failures
- if multiple heartbeats are necessary before declaring a leader dead, then the domain of unavailability is not just 500ms but 500ms x N, N = number of heartbeats
Repeating myself again, it’s more important to know how long it does take to detect and declare a Raft leader dead rather than how long it take to elect a leader.
Kudu does not replicate the on-disk storage of a tablet, but rather just its operation log. The physical storage of each replica of a tablet is fully decoupled. This yields several advantages
This is an excellent design choice. By decoupling the WAL and the storage format, one can:
- optimize the storage engine independently from the higher WAL replication layer
- change the storage engine implementation over time without impacting client API
Next, all the 3.3.1 Configuration Change chapter in the paper discusses about how to increase replication factor efficiently and in a robust manner. This scenario is quite rare but can occur in production. The proposed design is to rely on a one-by-one algorithm. If the current replication factor is 3 and we want to increase it to 5, the idea is first to increase it to 4. So we have the complete path 3 → 4 then 4 → 5.
The issue is when increasing from 3 → 4, the new replica has not received yet all the data and WAL from the leader but it can already participate as a Raft VOTER. Now if one of the original replica fails during the data transfer, strict majority of 4 VOTER is 3, including the pending joining replica which isn’t fully functional yet. So there is a risk of unavailability.
To solve this issue, the paper proposes to introduce the idea of PRE_VOTER e.g. the new replica does receive live updates from the Raft leader but does not count as a voter until it is fully functional.
Does this smart behavior remind you of Apache Cassandra bootstrapping new node and moving data around ? The new nodes does receive new updates as well as the existing data by streaming but does not account for the requested consistency level. Smart ideas get re-used!
D. The Master role
Kudu’s central master process has several key responsibilities:
- Act as a catalog manager, keeping track of which tables and tablets exist, as well as their schemas, desired replication levels, and other metadata. When tables are created, altered, or deleted, the Master coordinates these actions across the tablets and ensures their eventual completion.
- Act as a cluster coordinator, keeping track of which servers in the cluster are alive and coordinating redistribution of data after server failures.
- Act as a tablet directory, keeping track of which tablet servers are hosting replicas of each tablet
The master server fulfils the similar role of:
- Apache Cassandra system_xxx keyspaces for storing metadata
- Apache Cassandra Gossip protocol to know which server is alive/dead and which server is responsible for which token range of data
I’ll not dig into the details of how the Master manages the catalog metadata and all the failure modes. All you should know is the Master itself uses Raft to replicate the catalog metadata to backup Masters that act as Raft followers. Again this design is quite different from the masterless/peer-to-peer architecture of Apache Cassandra.
A critical design point of Kudu is that, while the Master is the source of truth about catalog information, it is only an observer of the dynamic cluster state. The tablet servers themselves are always authoritative about the location of tablet replicas, the current Raft configuration, the current schema version of a tablet, etc…
This design choice leaves much responsibility in the hands of the tablet servers themselves. For example, rather than detecting tablet server crashes from the Master, Kudu instead delegates that responsibility to the Raft LEADER replicas of any tablets with replicas on the crashed machine
Indeed, the Master role is limited to catalog management. All the failure detection and failover responsibility is achieved locally by the Raft LEADER of each tablet. This is a classical multi-master/one-master-per-shard architecture
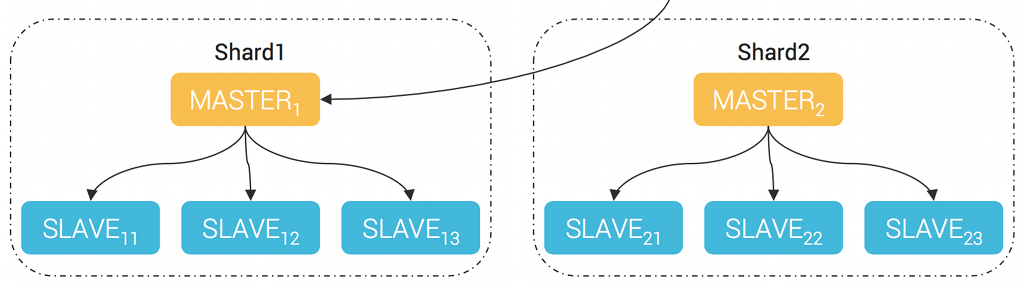
Multi Master
In order to efficiently perform read and write operations without intermediate network hops, clients query the Master for tablet location information. Clients are “thick” and maintain a local metadata cache which includes their most recent information about each tablet they have previously accessed, including the tablet’s partition key range and its Raft configuration. At any point in time, the client’s cache may be stale; if the client attempts to send a write to a server which is no longer the leader for a tablet, the server will reject the request. The client then contacts the Master to learn about the new leader. In the case that the client receives a network error communicating with its presumed leader, it follows the same strategy, assuming that the tablet has likely elected a new leader.
To reduce network round-trips Apache Kudu clients are smart and keep some cluster topology information. However, contrary to Apache Cassandra drivers with its control connection that allow them to be notified of any topology or schema change, Kudu clients need to query the Master whenever it detects that its metadata are staled.
V Storage Engine
A. Overview
Due to this decoupling, we are exploring the idea of providing the ability to select an underlying storage layout on a per-table, per-tablet or even per-replica basis – a distributed analogue of Fractured Mirrors, as proposed in [26]. However, we currently offer only a single storage layout, described in this section.
Pluggable storage engine ! A long requested feature for Apache Cassandra. The idea has been implemented by late Riak which offers 2 distinct storage engines.
The implementation of tablet storage in Kudu addresses several goals:
- Fast columnar scans – In order to provide analytic performance comparable to best-of-breed immutable data formats such as Parquet and ORCFile[7], it’s critical that the majority of scans can be serviced from efficiently encoded columnar data files
- Low-latency random updates – In order to provide fast access to update or read arbitrary rows, we require O(lg n) lookup complexity for random access
- Consistency of performance – Based on our experiences supporting other data storage systems, we have found that users are willing to trade off peak performance in order to achieve predictability
Goals 1. and 2. are contradicting. No single storage engine can address both requirements efficiently. The hint here is that Apache Kudu may implement 2 distinct storage structures to meet the requirements.
B. MemRowSets
Tablets in Kudu are themselves subdivided into smaller units called RowSets. Some RowSets exist in memory only, termed MemRowSets, while others exist in a combination of disk and memory, termed DiskRowSets.
…
…
At any point in time, a tablet has a single MemRowSet which stores all recently-inserted rows. Because these stores are entirely in-memory, a background thread periodically flushes MemRowSets to disk.
…
…
MemRowSets are implemented by an in-memory concurrent B-tree with optimistic locking, broadly based off the design of MassTree[22]
Reading all this should remind you of Apache Cassandra MemTable(~MemRowSet) and SSTable(~DiskRowSet). The concept of flushing MemRowSet into DiskRowSet is quite common.
C. DiskRowSets
When MemRowSets flush to disk, they become DiskRowSets. While flushing a MemRowSet, we roll the DiskRowSet after each 32 MB of IO. This ensures that no DiskRowSet is too large, thus allowing efficient incremental compaction as described later in Section 4.10.
Ok so here we are, compaction!
A DiskRowSet is made up of two main components: base data and delta stores. The base data is a column-organized representation of the rows in the DiskRowSet.
…
…
Several of the page formats supported by Kudu are common with those supported by Parquet, and our implementation shares much code with Impala’s Parquet library.
This is the confirmation that Apache Kudu has 2 storage formats, one for the columnar data store (base data) and one designed for low latency row-based random updates (delta stores). As expected the columnar data store has a lot in common with Apache Parquet.
In addition to flushing columns for each of the user-specified columns in the table, we also write a primary key index column, which stores the encoded primary key for each row. We also flush a chunked Bloom filter[10] which can be used to test for the possible presence of a row based on its encoded primary key.
Partition key index + Bloom filter. Those data structures are present in nearly every distributed technologies.
D. DeltaFiles
Because columnar encodings are difficult to update in place, the columns within the base data are considered immutable once flushed. Instead, updates and deletes are tracked through structures termed delta stores. Delta stores are either in-memory DeltaMemStores, or on-disk DeltaFiles.
Here Apache Kudu applies the same design as for RowSets. In memory delta store is subject to flush on disk and on disk delta store is subject to compaction into base data.
A DeltaMemStore is a concurrent B-tree which shares the implementation described above. A DeltaFile is a binary-typed column block. In both cases, delta stores maintain a mapping from (row offset, timestamp) tuples to RowChangeList records. The row offset is simply the ordinal index of a row within the RowSet – for example, the row with the lowest primary key has offset 0. The timestamp is the MVCC timestamp assigned when the operation was originally written. The RowChangeList is a binary-encoded list of changes to a row, for example indicating
SET column id 3 = ‘foo’ or DELETE
Implementation details. Please note how Apache Kudu also uses timestamps for conflict resolution (timestamp in Apache Kudu derives from HybridTime, not from the plain wall clock).
When servicing an update to data within a DiskRowSet, we first consult the primary key index column. By using its embedded B-tree index, we can efficiently seek to the page containing the target row. Using page-level metadata, we can determine the row offset for the first cell within that page. By searching within the page (eg via in-memory binary search) we can then calculate the target row’s offset within the entire DiskRowSet. Upon determining this offset, we insert a new delta record into the rowset’s DeltaMemStore.
This whole paragraph is important to understand write performance characteristics of Apache Kudu. Contrary to Apache Cassandra where writes are just translated into sequential append to CommitLog then updating the in memory Memtable, an update in Apache Kudu involves a lot of reads:
- primary key index read
- seeking page containing target row
- page level metadata read to determine row offset within DiskRowSet
Whether some of those data structure are held in memory or in OS page cache does not change the fact that writing requires at least reads in best case. In the presence of an heavy workload where memory becomes scarce, those reads can revert to plain disk seek and add extra latency to the update operations.
E. INSERT path
As described previously, each tablet has a single MemRowSet which is holds recently inserted data; however, it is not sufficient to simply write all inserts directly to the current MemRowSet, since Kudu enforces a primary key uniqueness constraint. In other words, unlike many NoSQL stores, Kudu differentiates INSERT from UPSERT
Insert operations in Apache Kudu do differ from Update. They are not semantically equivalent.
In order to cull the set of DiskRowSets to consult on an INSERT operation, each DiskRowSet stores a Bloom filter of the set of keys present
Bloom filters to the rescue ! This is the most widely used and most powerful data structures ever for Big Data. Even more used than CRDT or HyperLogLog.
Additionally, for each DiskRowSet, we store the minimum and maximum primary key, and use these key bounds to index the DiskRowSets in an interval tree. This further culls the set of DiskRowSets to consult on any given key lookup.
Implementation detail to eliminate further non matching DiskRowSets.
For any DiskRowSets that are not able to be culled, we must fall back to looking up the key to be inserted within its encoded primary key column. This is done via the embedded B-tree index in that column, which ensures a logarithmic number of disk seeks in the worst case. Again, this data access is performed through the page cache, ensuring that for hot areas of key space, no physical disk seeks are needed.
When relying on page cache, you better have a lot of RAM to avoid ever hitting disk, it can be quite painful. Nothing is said about large size DiskRowSets which create giant primary key index files. In this case, OS page cache may not be sufficient Kudu may resort to hitting disk even if the disk seeks are amortized by the logarithmic complexity.
F. READ path
When reading data from a DiskRowSet, Kudu first determines if a range predicate on the scan can be used to cull the range of rows within this DiskRowSet. For example, if the scan has set a primary key lower bound, we perform a seek within the primary key column in order to determine alower bound row offset; we do the same with any upper bound key. This converts the key range predicate into a row offset range predicate, which is simpler to satisfy as it requires no expensive string comparisons.
Apache Kudu has an interesting system that translate range of primary keys into offset bounds. Of course what is not mentioned in the paper is that this translation between primary key ranges and offsets is done using the primary key index, thus extra reads in memory/page cache or on disk in the worst case. There is no magic.
Next, Kudu performs the scan one column at a time. First, it seeks the target column to the correct row offset (0, if no predicate was provided, or the start row, if it previously determined a lower bound). Next, it copies cells from the source column into our row batch using the page-encoding specific decoder. Last, it consult the delta stores to see if any later updates have replaced cells with newer versions, based on the current scan’s MVCC snapshot, applying those changes to our in-memory batch as necessary
This is the real trade-off paid by Apache Kudu to be able to allow random atomic updates to row. At read time, Kudu needs to read from 2 different data stores (the columnar storage + the delta set) to reconcile the data based on timestamp. And this even not mentioning all the index data structures that need to be read in order to optimize disk access.
G. DeltaSet compaction
Because deltas are not stored in a columnar format, the scan speed of a tablet will degrade as ever more deltas are applied to the base data. Thus, Kudu’s background maintenance manager periodically scans DiskRowSets to find any cases where a large number of deltas (as identified by the ratio between base data row count and delta count) have accumulated, and schedules a delta compaction operation which merges those deltas back into the base data columns.
Similar to the default SizeTieredCompactionStrategy in Apache Cassandra, Apache Kudu uses some simple heuristic (base/delta row count ratio) to trigger compaction of the deltas back into the base data. If most of the changes in the deltas only impact a few columns, an obvious optimization would be to compact only the data files of those columns.
H. RowSet compaction
In addition to compacting deltas into base data, Kudu also periodically compacts different DiskRowSets together in a process called RowSet compaction. This process performs a keybased merge of two or more DiskRowSets, resulting in a sorted stream of output rows.
The RowSet compaction also helps removing deleted rows. Unlike Apache Cassandra which needs to keep tombstones before a round of repair is performed, Apache Kudu does not need tombstones because of its master/slave architecture.
The output is written back to new DiskRowSets, again rolling every 32 MB, to ensure that no DiskRowSet in the system is too large.
This mean that for a Tablet node density of 1Tb, there will be ~32 000 DiskRowSet files + ~32 000 Bloom filter files + ~32 000 primary index files. It’s a lot of file handles …
I. Maintenance tasks
These operations are performed by a pool of maintenance threads that run within the tablet server process. Toward the design goal of consistent performance, these threads run all the time, rather than being triggered by specific events or condition
…
…
In order to select DiskRowSets to compact, the maintenance scheduler solves an optimization problem: given an IO budget (typically 128 MB), select a set of DiskRowSets such that compacting them would reduce the expected number of seeks, as described above. This optimization turns out to be a series of instances of the well-known integer knapsack problem, and is able to be solved efficiently in a few milliseconds
The knapsack problem is by nature a combinatorial optimization problem for which there cannot be any algorithm to give an exact answer. There are only heuristics that approximate the optimal solution. Some of them are good enough for this kind of task. There is no absolute requirement to pick the optimal sets of data files for compaction. Compacting any set of data file that yields large latency gain at read time is more than sufficient.
Because the maintenance threads are always running small units of work, the operations can react quickly to changes in workload behavior. For example, when insertion workload increases, the scheduler quickly reacts and flushes in-memory stores to disk. When the insertion workload reduces, the server performs compactions in the background to increase performance for future writes. This provides smooth transitions in performance, making it easier for developers and operators to perform capacity planning and estimate the latency profile of their workloads.
Apache Kudu scheduler is capable to adapt itself to the current workload of the machine, which is a quite nice feature. I’d like to see such feature in Apache Cassandra where compaction tasks are only scheduled when there is enough bandwidth to ensure the compaction does not get stuck forever.
VI Conclusion
To sum up, I would say that the design of Apache Kudu borrows a lot from existing technologies, some good ideas are re-used, as well as known data structures like Bloom filters, B-tree index or Apache Parquet columnar storage. The only new idea is the implementation of HybridTime (we’ll have another blog post discussing that later).
In term of performance, Apache Kudu is:
- not as fast as Apache Cassandra (or even Apache HBase) for writes operations: this is mainly because of unicity constraint that requires read-before-write plus a round of Raft consensus for each write
- not as fast as Apache Parquet for full analytics workload because Apache Kudu needs to merge the data set and deltas at read time to reconcile data
- not as highly available as Apache Cassandra given its multi-master architecture
however, given those trade-offs, Apache Kudu can:
- perform full analytics workloads on large datasets much more efficiently than Apache Cassandra
- perform random row update which Apache Parquet cannot do
At the end of the day, since every technology is bound by the time & space constraints of distributed systems, there is no silver bullet, there are only conscious design trade-offs to enable some features by giving up some others.
Thank you for that great post. A lot of points about Kudu are more clear now, by reading it as comparison to Cassandra.
couple of points
Say for analytics one can make the tables already compacted and read only . In Netezza like DB people always do grooming for better performance . grooming is another name for compaction.
With Kudu we can co-locate diff tables with primary index like Terdata,Netezza etc. Gives a better design,flexibility in addition to all the benefits of an immutable columnar format.
very interesting thank you !
An Amazing read. It’s like a refresher of distributed systems. I request you to please make one like this for Cassandra vs HBase
Short answer, HBase has no future (as well as the whole Hadoop stack, too complex)