This blog post is a technical deep dive into the new cool SASI index that enables full text search as well as faster multi-criteria search in Cassandra (introduced since Cassandra 3.4 but I recommend Cassandra 3.5 at least because of critical bugs being fixed).
For the remaining of this post Cassandra == Apache Cassandra™
First, a big thank to Sam Tunnicliffe of Datastax and Pavel Yaskevich without whom this post is not possible.
The post divides itself into 10 parts. Below is the table of content:
- A) What is SASI ?
- B) SASI Syntax and Usage
- 1) Text data types
- 2) Other data types
- 3) All data types
- C) SASI Life-Cycle
- D) Write Path
- 1) In Memory
- 2) On Flush
- E) On Disk Data Format & Layout
- 1) Non SPARSE mode Layout
- 2) Header Block
- 3) Non SPARSE Data Block
- 4) Non SPARSE Term Block
- 5) Common TokenTree Block
- 6) SPARSE mode Layout
- 7) SPARSE Data Block
- 8) SPARSE Term Block
- 9) Pointer Block
- 10) Meta Data Info
- F) Read Path
- 1) Query Planner
- 2) Cluster Read Path
- 3) Local Read Path
- G) Disk Space Usage
- H) Some Performance Benchmarks
- I) SASI vs Search Engines
- J) SASI Trade-Offs
A) What is SASI ?
SASI stands for SSTable-Attached Secondary Index, e.g. the life-cycle of SASI index files are the same as the one of corresponding SSTables. SASI is a contribution from a team of engineers, below is the list of all contributors:
- Pavel Yaskevich
- Jordan West
- Jason Brown
- Mikhail Stepura
- Michael Kjellman
SASI is not yet-another-implementation of Cassandra secondary index interface, it introduces a new idea: let the index file follows the life-cycle of the SSTable. It means that whenever an SSTable is created on disk, a corresponding SASI index file is also created. When are SSTables created ?
- during normal flush
- during compaction
- during streaming operations (node joining or being decommissioned)
To enable this new architecture, the Cassandra source code had to be modified to introduce the new SSTableFlushObserver class whose goal is to intercept SSTable flushing and generates the corresponding SASI index file.
B) SASI Syntax and Usage
SASI uses the standard CQL syntax to create a custom secondary index. Let’s see all the available index options.
1) For text data types (text, varchar & ascii)
Indexing mode:
-
PREFIX: allows matching text value by:
- prefix using the
LIKE 'prefix%'syntax - exact match using equality (=)
- prefix using the
-
CONTAINS: allows matching text value by:
- prefix using the
LIKE 'prefix%'syntax (iforg.apache.cassandra.index.sasi.analyzer.NonTokenizingAnalyzeris used) - suffix using the
LIKE '%suffix'syntax - substring using the
LIKE '%substring%'syntax - exact match using equality (=) (if
org.apache.cassandra.index.sasi.analyzer.NonTokenizingAnalyzeris used)
- prefix using the
Indexing mode:
analyzed(true/false): activate text analysis. Warning: lower-case/upper-case normalization requires an analyzer
Analyzer class (analyzer_class):
org.apache.cassandra.index.sasi.analyzer.NonTokenizingAnalyzerwith options:case_sensitive(true/false): search using case sensitivitynormalize_lowercase(true/false): store text as lowercasenormalize_uppercase(true/false): store text as uppercase
org.apache.cassandra.index.sasi.analyzer.StandardAnalyzerwith options:tokenization_locale: locale to be used for tokenization, stemming and stop words skippingtokenization_enable_stemming(true/false): enable stemming (locale dependent)tokenization_skip_stop_words(true/false): skip indexing stop words (locale dependent)tokenization_normalize_lowercase(true/false): store text as lowercasetokenization_normalize_uppercase(true/false): store text as uppercase
// Full text search on albums title
CREATE CUSTOM INDEX albums_title_idx ON music.albums(title)
USING 'org.apache.cassandra.index.sasi.SASIIndex'
WITH OPTIONS = {
'mode': 'CONTAINS',
'analyzer_class': 'org.apache.cassandra.index.sasi.analyzer.StandardAnalyzer',
'tokenization_enable_stemming': 'true',
'tokenization_locale': 'en',
'tokenization_skip_stop_words': 'true',
'analyzed': 'true',
'tokenization_normalize_lowercase': 'true'
};
// Full text search on artist name with neither Tokenization nor case sensitivity
CREATE CUSTOM INDEX albums_artist_idx ON music.albums(artist)
USING 'org.apache.cassandra.index.sasi.SASIIndex'
WITH OPTIONS = {
'mode': 'PREFIX',
'analyzer_class': 'org.apache.cassandra.index.sasi.analyzer.NonTokenizingAnalyzer',
'case_sensitive': 'false'
};
1) For other data types (int, date, uuid …)
Indexing mode:
-
PREFIX: allows matching values by:
- equality (=)
- range ( <, ≤, >, ≥ )
-
SPARSE: allows matching sparse index values by:
- equality (=)
- range ( <, ≤, >, ≥ )
There is an important remark about SPARSE mode. By sparse, it means that for each indexed value, there are very few (maximum 5 actually) matching rows. If there are more than 5 matching rows, an exception similar to the one below will be thrown:
java.io.IOException: Term - 'xxx' belongs to more than 5 keys in SPARSE mode, which is not allowed.
SPARSE mode has been designed primarily to index very unique values and allow efficient storage and efficient range query. For example, if you’re storing user account and creates an index on the account_creation_date column (millisecond precision), it’s likely that you’ll have very few matching user(s) for a given date. However, you’ll be able to search user whose account has been created between a wide range of date (WHERE account_creation_date > xxx AND account_creation_date < yyy) in a very efficient manner.
// Range search on numeric value
CREATE CUSTOM INDEX albums_year_idx ON music.albums(year)
USING 'org.apache.cassandra.index.sasi.SASIIndex'
WITH OPTIONS = {'mode': 'PREFIX'};
3) For all data types
max_compaction_flush_memory_in_mb: defines the max size for theOnDiskIndexstructure to be kept in memory during compaction. If the index exceeds this size, it will be flushed to disk in segments and merged together in a second pass to create the finalOnDiskIndexfile
C) SASI Life-Cycle
When a mutation is pushed to a node, first it is written into a CommitLog then put into MemTable. At the same time, the mutation is indexed into SASI in-memory index structure (IndexMemtable)
public long index(DecoratedKey key, ByteBuffer value)
{
if (value == null || value.remaining() == 0)
return 0;
AbstractType<?> validator = index.columnIndex.getValidator();
if (!TypeUtil.isValid(value, validator))
{
int size = value.remaining();
if ((value = TypeUtil.tryUpcast(value, validator)) == null)
{
logger.error("Can't add column {} to index for key: {}, value size {}, validator: {}.",
index.columnIndex.getColumnName(),
index.columnIndex.keyValidator().getString(key.getKey()),
FBUtilities.prettyPrintMemory(size),
validator);
return 0;
}
}
return index.add(key, value);
}
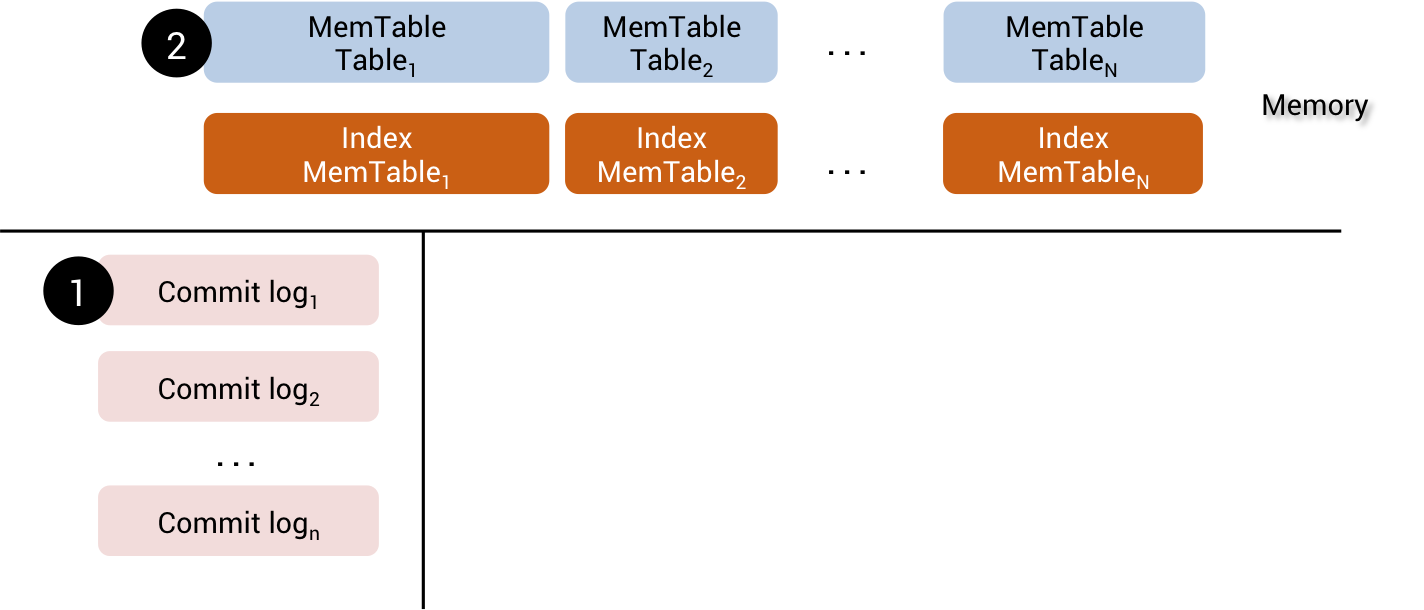
SASI IndexMemtable
Later on, when MemTables are flushed to disk, SASI will create one OnDiskIndex file for each SSTable
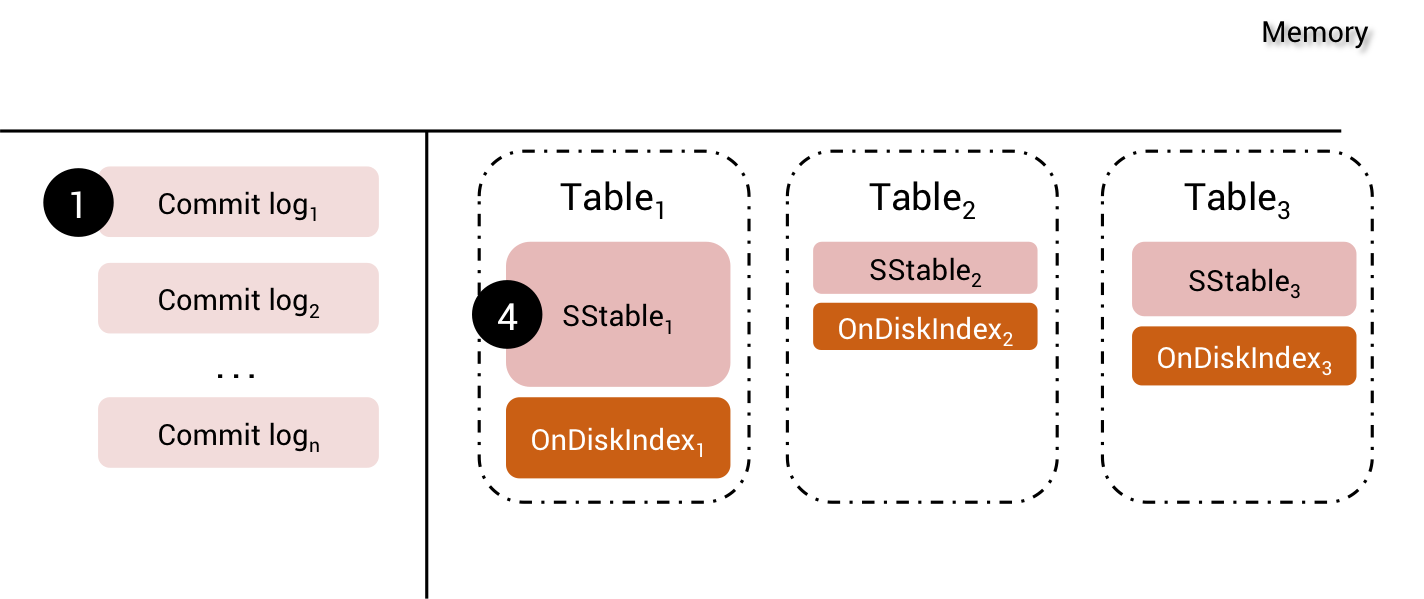
SASI OnDiskIndex
This write-path applies to:
- normal mutations
- read repairs
- normal repairs
- hints replays
- streaming operations (node joining, node decommissioned)
If SSTables are compacted, the OnDiskIndex files will also follow the compaction cycle and will be merged into 1 big final OnDiskIndex file

SASI OnDiskIndex Compaction
D) Write Path
1) In Memory
When a mutation is appended into MemTable, the AtomicBTreePartition.RowUpdater.apply() methods will be invoked and the mutation is passed to the appropriate indexer
public Row apply(Row insert)
{
Row data = Rows.copy(insert, builder(insert.clustering())).build();
indexer.onInserted(insert);
this.dataSize += data.dataSize();
this.heapSize += data.unsharedHeapSizeExcludingData();
if (inserted == null)
inserted = new ArrayList<>();
inserted.add(data);
return data;
}
public Row apply(Row existing, Row update)
{
Row.Builder builder = builder(existing.clustering());
colUpdateTimeDelta = Math.min(colUpdateTimeDelta, Rows.merge(existing, update, builder, nowInSec));
Row reconciled = builder.build();
indexer.onUpdated(existing, reconciled);
dataSize += reconciled.dataSize() - existing.dataSize();
heapSize += reconciled.unsharedHeapSizeExcludingData() - existing.unsharedHeapSizeExcludingData();
if (inserted == null)
inserted = new ArrayList<>();
inserted.add(reconciled);
discard(existing);
return reconciled;
}
In the case of SASI, it will call IndexMemtable.index() method. Depending on the indexed column type and index mode, an appropriate data-structure is used to store the indexed values:
| Index Mode | Data Type | Data Structure | Usage syntax |
|---|---|---|---|
| PREFIX | text, ascii, varchar | Guava ConcurrentRadixTree |
name LIKE 'John%' name = 'Johnathan' |
| CONTAINS | text, ascii, varchar | Guava ConcurrentSuffixTree |
name LIKE 'John%' * name LIKE '%nathan' name LIKE '%nat%' name = 'Johnathan' * |
| PREFIX | others (int, date, uuid ...) | Modified JDK ConcurrentSkipListSet |
age = 20 age >= 20 AND age <= 30 |
| SPARSE | others (int, date, uuid ...) | Modified JDK ConcurrentSkipListSet |
event_date >= '2016-03-23 00:00:00+0000' AND event_date <= '2016-04-23 00:00:00+0000' |
* only if org.apache.cassandra.index.sasi.analyzer.NonTokenizingAnalyzer is used
Please note that SASI does not intercept DELETE for indexing. Indeed the resolution and reconciliation of deleted data is let to Cassandra at read time. SASI only indexes INSERT and UPDATE
2) On Flush
When Cassandra is ready to flush SSTables to disk, it will call SSTableWriter.observers() to get a list of all observers. Currently only SASI registers an observer and it is the PerSSTableIndexWriter class. Native secondary index doesn't implement any observer:
private static Collection<SSTableFlushObserver> observers(Descriptor descriptor,
Collection<Index> indexes,
OperationType operationType)
{
if (indexes == null)
return Collections.emptyList();
List<SSTableFlushObserver> observers = new ArrayList<>(indexes.size());
for (Index index : indexes)
{
SSTableFlushObserver observer = index.getFlushObserver(descriptor, operationType);
if (observer != null)
{
observer.begin();
observers.add(observer);
}
}
return ImmutableList.copyOf(observers);
}
Then, for each new partition to be written to disk, BigTableWriter.append() will call each observer startPartition() method, passing the offset of the current partition in the current SSTable:
public RowIndexEntry append(UnfilteredRowIterator iterator)
{
DecoratedKey key = iterator.partitionKey();
if (key.getKey().remaining() > FBUtilities.MAX_UNSIGNED_SHORT)
{
logger.error("Key size {} exceeds maximum of {}, skipping row", key.getKey().remaining(), FBUtilities.MAX_UNSIGNED_SHORT);
return null;
}
if (iterator.isEmpty())
return null;
long startPosition = beforeAppend(key);
observers.forEach((o) -> o.startPartition(key, iwriter.indexFile.position()));
...
}
For each row in the partition, the method org.apache.cassandra.db.ColumnIndex.add() is called and will notify each observer of the row content to be indexed
private void add(Unfiltered unfiltered) throws IOException
{
long pos = currentPosition();
if (firstClustering == null)
{
// Beginning of an index block. Remember the start and position
firstClustering = unfiltered.clustering();
startPosition = pos;
}
UnfilteredSerializer.serializer.serialize(unfiltered, header, writer, pos - previousRowStart, version);
// notify observers about each new row
if (!observers.isEmpty())
observers.forEach((o) -> o.nextUnfilteredCluster(unfiltered));
...
}
When reaching the end of the MemTable, the method SSTableWriter.finish() is invoked to trigger the actual flush. This code also notifies any registered observer to finalize their work
public SSTableReader finish(boolean openResult)
{
setOpenResult(openResult);
txnProxy.finish();
observers.forEach(SSTableFlushObserver::complete);
return finished();
}
From SASI side, the indexing part is done inside the class PerSSTableIndexWriter.
All the indexing logic is done by method PerSSTableIndexWriter.Index.add(). For each indexed value (called term in the source code), the analyzer class will split it into multiple tokens (if StandardAnalyzer is used) and pass the (term, partition key as token value, partition offset in SSTable) triplet to the class OnDiskIndexBuilder.
If the built OnDiskIndex size has not reach 1Gb, the next term is processed otherwise SASI will schedule an asynchronous flush of this partial segment to disk and start building a new one.
public void add(ByteBuffer term, DecoratedKey key, long keyPosition)
{
if (term.remaining() == 0)
return;
boolean isAdded = false;
analyzer.reset(term);
while (analyzer.hasNext())
{
ByteBuffer token = analyzer.next();
int size = token.remaining();
if (token.remaining() >= OnDiskIndexBuilder.MAX_TERM_SIZE)
{
logger.info("Rejecting value (size {}, maximum {}) for column {} (analyzed {}) at {} SSTable.",
FBUtilities.prettyPrintMemory(term.remaining()),
FBUtilities.prettyPrintMemory(OnDiskIndexBuilder.MAX_TERM_SIZE),
columnIndex.getColumnName(),
columnIndex.getMode().isAnalyzed,
descriptor);
continue;
}
if (!TypeUtil.isValid(token, columnIndex.getValidator()))
{
if ((token = TypeUtil.tryUpcast(token, columnIndex.getValidator())) == null)
{
logger.info("({}) Failed to add {} to index for key: {}, value size was {}, validator is {}.",
outputFile,
columnIndex.getColumnName(),
keyValidator.getString(key.getKey()),
FBUtilities.prettyPrintMemory(size),
columnIndex.getValidator());
continue;
}
}
currentBuilder.add(token, key, keyPosition);
isAdded = true;
}
if (!isAdded || currentBuilder.estimatedMemoryUse() < maxMemorySize)
return; // non of the generated tokens were added to the index or memory size wasn't reached
segments.add(getExecutor().submit(scheduleSegmentFlush(false)));
}
The reason to flush index file by segments is to avoid OutOfMemoryException. Once all segments are flushed, they will be stitched together to create the final OnDiskIndex file.
The memory threshold is defined in the method PerSSTableIndexWriter.maxMemorySize()
protected long maxMemorySize(ColumnIndex columnIndex)
{
// 1G for memtable and configuration for compaction
return source == OperationType.FLUSH ? 1073741824L : columnIndex.getMode().maxCompactionFlushMemoryInMb;
}
When the SSTable flush is complete, the method PerSSTableIndexWriter.complete() is called, it will trigger the stitching of index segments together, if there are more than 1 segments.
The stitching phase is necessary because the terms are sorted in each segment but not globally. The stitching process will help sorting the term globally and merge all the TokenTrees together to create the final index file.
public void complete(final CountDownLatch latch)
{
logger.info("Scheduling index flush to {}", outputFile);
getExecutor().submit((Runnable) () -> {
long start1 = System.nanoTime();
OnDiskIndex[] parts = new OnDiskIndex[segments.size() + 1];
try
{
// no parts present, build entire index from memory
if (segments.isEmpty())
{
scheduleSegmentFlush(true).call();
return;
}
// parts are present but there is something still in memory, let's flush that inline
if (!currentBuilder.isEmpty())
{
@SuppressWarnings("resource")
OnDiskIndex last = scheduleSegmentFlush(false).call();
segments.add(Futures.immediateFuture(last));
}
int index = 0;
ByteBuffer combinedMin = null, combinedMax = null;
for (Future<OnDiskIndex> f : segments)
{
OnDiskIndex part = f.get();
if (part == null)
continue;
parts[index++] = part;
combinedMin = (combinedMin == null || keyValidator.compare(combinedMin, part.minKey()) > 0) ? part.minKey() : combinedMin;
combinedMax = (combinedMax == null || keyValidator.compare(combinedMax, part.maxKey()) < 0) ? part.maxKey() : combinedMax;
}
OnDiskIndexBuilder builder = newIndexBuilder();
builder.finish(Pair.create(combinedMin, combinedMax),
new File(outputFile),
new CombinedTermIterator(parts));
}
catch (Exception | FSError e)
{
logger.error("Failed to flush index {}.", outputFile, e);
FileUtils.delete(outputFile);
}
finally
{
logger.info("Index flush to {} took {} ms.", outputFile, TimeUnit.NANOSECONDS.toMillis(System.nanoTime() - start1));
for (int segment = 0; segment < segmentNumber; segment++)
{
OnDiskIndex part = parts[segment];
if (part != null)
FileUtils.closeQuietly(part);
FileUtils.delete(outputFile + "_" + segment);
}
latch.countDown();
}
});
}
E) On Disk Data Format & Layout
1) Non SPARSE mode Layout
All the format of OnDiskIndex is described in the class OnDiskIndexBuilder. From a higher point of view, the OnDiskIndex layout for non SPARSE mode is:
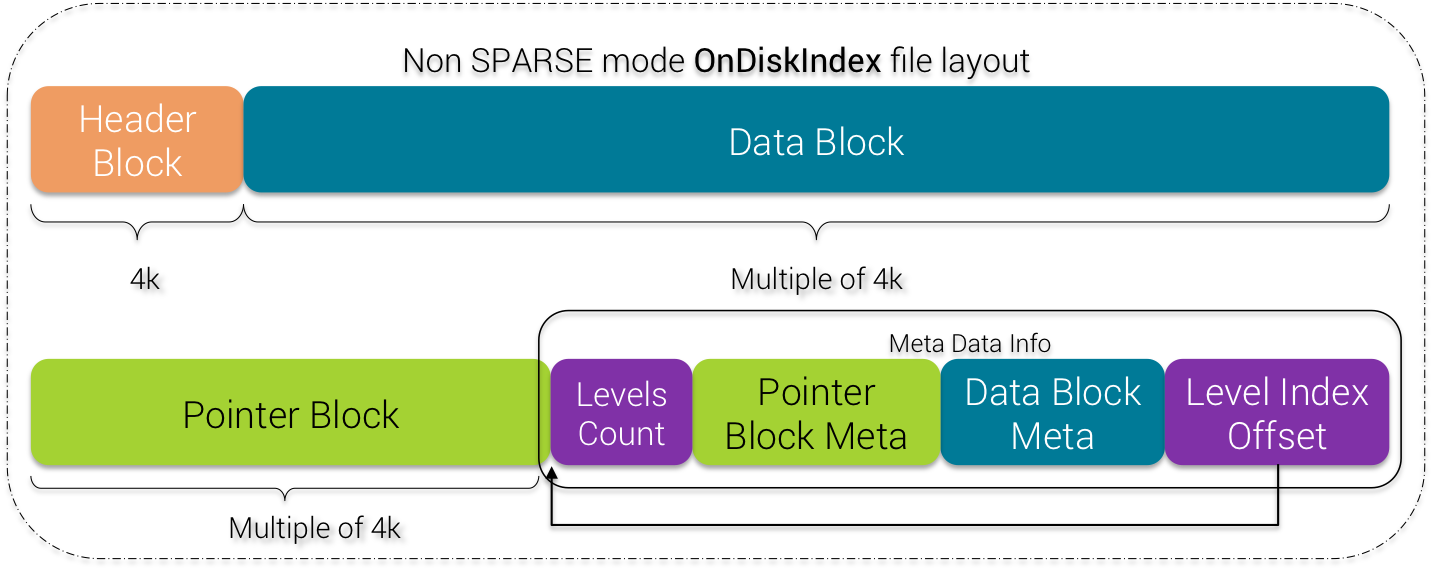
NON SPARSE mode OnDiskIndex
The Header Block contains general meta data information. The Data Block contains indexed data with matching token value(s) and offset(s). The Pointer Block contains pointers to lower levels. It can be seen as a binary tree whose goal is to help performing binary search quickly on terms.
Levels Count indicates the number of levels the current binary tree of pointers has
Pointer Block Meta and Data Block Meta contain offsets to pointer and data blocks to speed up disk access.
Level Index Offset is the offset from the beginning of the file of the whole meta data info block
Please notice that Header, Data and Pointer blocks length are multiple of 4k. This is purposely designed to align with block size on disk.
2) Header Block
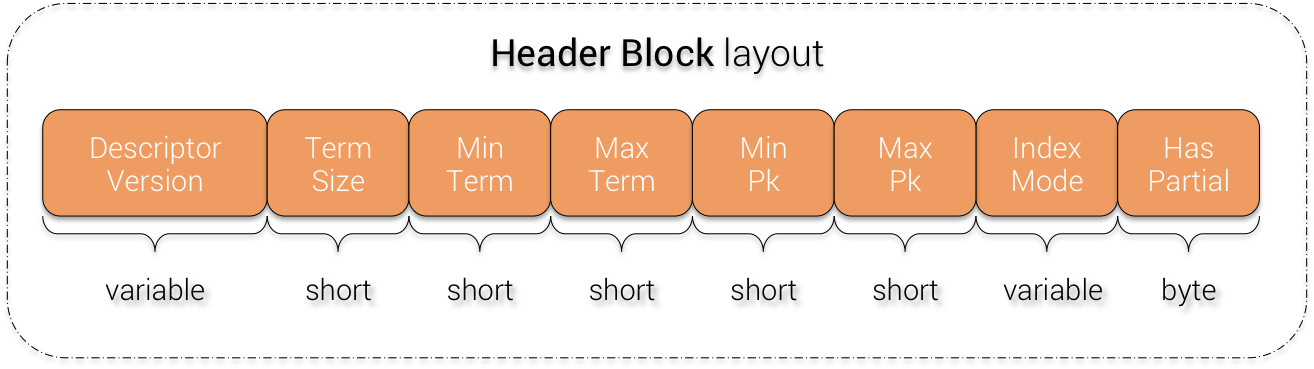
Header Block
The Descriptor Version is a currently hard-coded value: ab.
The Term Size depends on the indexed column data type:
| Data Type | Term Size |
|---|---|
| int, float | 4 |
| bigint, double, timestamp | 8 |
| uuid, timeuuid | 16 |
| all other types | -1 (variable size) |
The Min Term and Max Term represent respectively the minimum & maximum indexed value found in this index file. The indexed values are ordered by their type (text --> lexicographic ordering, timestamp --> date ordering , etc ...). Those min/max terms are useful for range queries and allow SASI to skip the entire index file if the [min - max] range does not match the one of the query
The Min Pk and Max Pk represent respectively the minimum & maximum partition keys of the matching partitions in this index files. Again they are used to skip index files if the search query specifies a partition key.
Index Mode is just the chosen index mode (PREFIX, CONTAINS or SPARSE)
Has Partial is a boolean flag introduced by CASSANDRA-11434 for backward compatibility and to enable prefix and equality match when using index mode CONTAINS with NonTokenizingAnalyzer. More details on this in the next chapter.
3) Non SPARSE Data Block
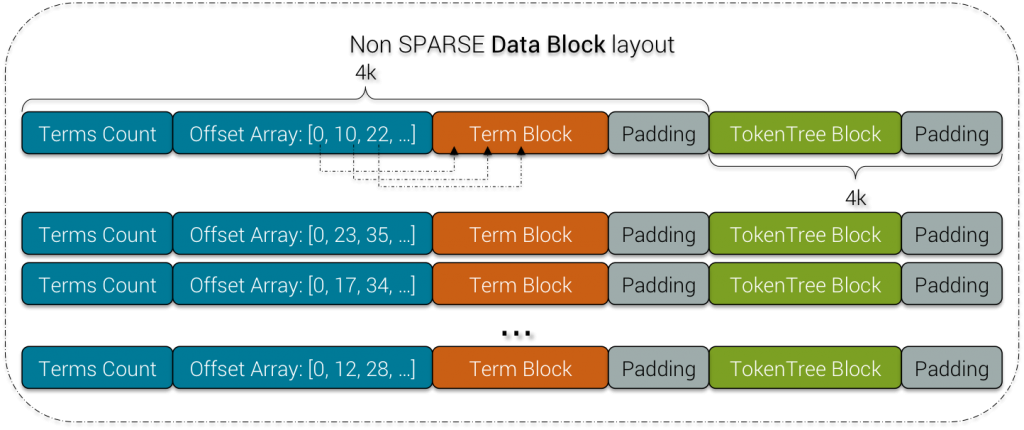
Non SPARSE Data Block
Terms Count represents the number of terms (indexed values) in the next Term Block.
Offsets Array is an array of relative offsets for each entry in the Term Block beginning from the current position
Term Block is a block containing terms and their metadata, it is described below.
TokenTree Block is a block containing a binary tree of token values, it is described below.
Padding is there to fill a block worth of 4k
4) Non SPARSE Term Block

Non SPARSE Term Block
Each entry in the Non SPARSE Term Block is composed of a Partial Bit which tells whether the current term represent the original term or is one of its suffixes. The term itself is then written, followed by a 0x0 byte and then a TokenTree offset. This offset point to a node in the TokenTree Block that follow this Term Block.
Terms Count : 20, Offsets [0, 9, 21, 34, 43, 54, 63, 73, 85, 99, 109, 125, 133, 143, 151, 164, 179, 193, 204, 215]
Data Term (partial ? true) : an. 0x0, TokenTree offset : 0
Data Term (partial ? true) : athan. 0x0, TokenTree offset : 80
Data Term (partial ? true) : atrick. 0x0, TokenTree offset : 160
Data Term (partial ? true) : ck. 0x0, TokenTree offset : 240
Data Term (partial ? true) : elen. 0x0, TokenTree offset : 320
Data Term (partial ? true) : en. 0x0, TokenTree offset : 400
Data Term (partial ? true) : han. 0x0, TokenTree offset : 480
Data Term (partial ? false) : helen. 0x0, TokenTree offset : 560
Data Term (partial ? true) : hnathan. 0x0, TokenTree offset : 640
Data Term (partial ? true) : ick. 0x0, TokenTree offset : 720
Data Term (partial ? false) : johnathan. 0x0, TokenTree offset : 800
Data Term (partial ? true) : k. 0x0, TokenTree offset : 880
Data Term (partial ? true) : len. 0x0, TokenTree offset : 960
Data Term (partial ? true) : n. 0x0, TokenTree offset : 1040
Data Term (partial ? true) : nathan. 0x0, TokenTree offset : 1136
Data Term (partial ? true) : ohnathan. 0x0, TokenTree offset : 1216
Data Term (partial ? false) : patrick. 0x0, TokenTree offset : 1296
Data Term (partial ? true) : rick. 0x0, TokenTree offset : 1376
Data Term (partial ? true) : than. 0x0, TokenTree offset : 1456
Data Term (partial ? true) : trick. 0x0, TokenTree offset : 1536
Please notice that terms are sorted inside each Term Block as well as between different Term Blocks.
5) Common TokenTree Block
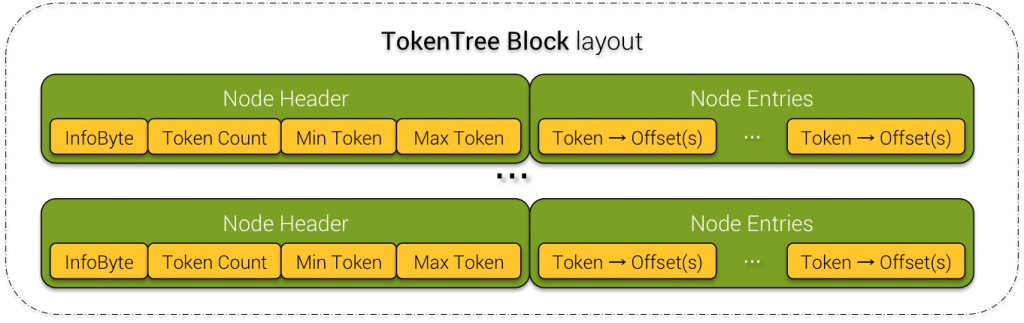
TokenTree Block
Node Header:
- InfoByte is a flag. 0 means the current node is a Root node. 1 means the current node is the Leaf node and 3 means the current node is a last Leaf node or a Root node for a single node tree.
- Token Count give the number of matching token values for the given term.
- Min Token and Max Token are self-explanatory
The Node Entries block contains a sequence of (token value, offset(s)). Because of possible (although extremely rare) hash collision, a single token value can refer to multiple partition keys, thus multiple offsets in the SSTable.
Root Header -- Infobyte : 3, tokens count : 3, min token : -4628280296660234682, max token : 5209625165902544754
token : -4628280296660234682, offset data : 626062
token : -276633795570262675, offset data : 1236735
token : 5209625165902544754, offset data : 2004475
...
Root Header -- Infobyte : 0, tokens count : 2, min token : 1002236203180810244, max token : 9166816315445099933
Child offsets: [4096, 8192, 12288]
Leaf Header -- Infobyte : 1, tokens count : 248, min token : -9120558309355192568, max token : 947122733220850512
token : -9120558309355192568, offset data : 13568
token : -9115699645219380894, offset data : 14118
token : -9110053775482800927, offset data : 15042
token : -9087332613408394714, offset data : 17704
...
Leaf Header -- Infobyte : 1, tokens count : 194, min token : 1002236203180810244, max token : 9139944811025517925
token : 1002236203180810244, offset data : 1416779
token : 1079301330783368458, offset data : 1427152
token : 1136093249390936984, offset data : 1434834
token : 1165503468422334041, offset data : 1438905
...
Leaf Header -- Infobyte : 3, tokens count : 1, min token : 9166816315445099933, max token : 9166816315445099933
token : 9166816315445099933, offset data : 2567147
Inside the Term Block, there are TokenTree offsets that point to entries inside the TokenTree Block. With this layout, each term can refer to a list of partition offsets in the corresponding SSTable for lookup.

Term - TokenTree Link
6) SPARSE mode Layout
If you're choosing the index SPARSE mode, the layout is slightly different:
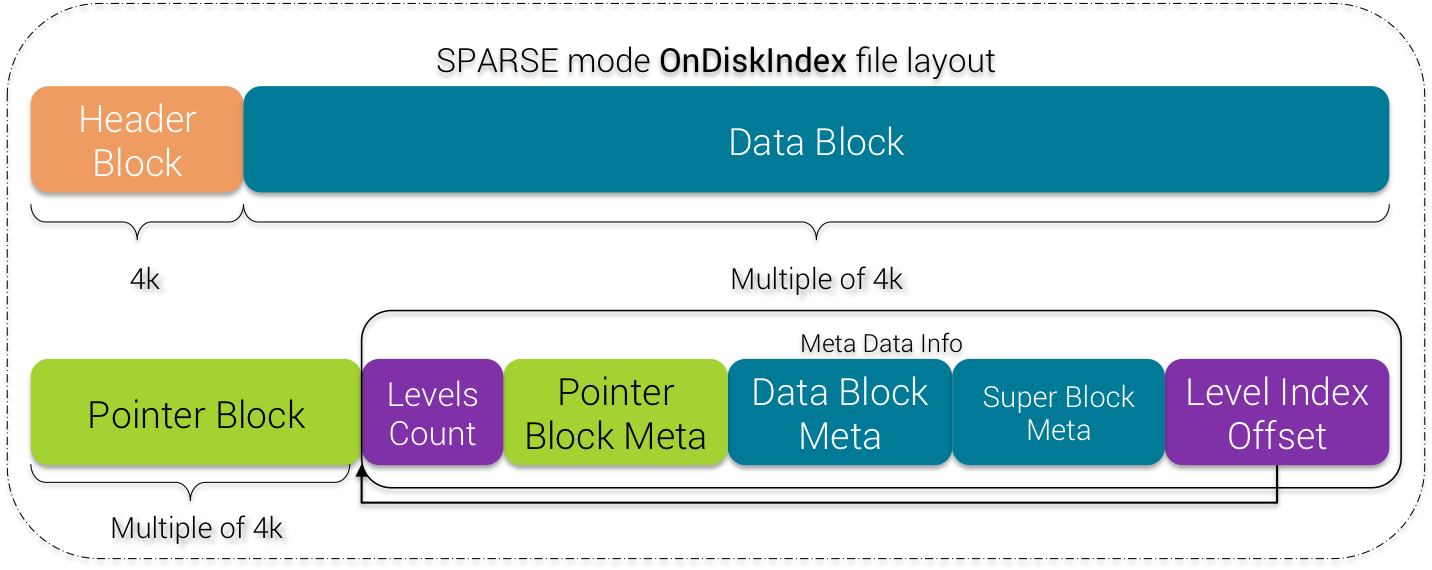
SPARSE mode OnDiskIndex
There is a new Super Block Meta that is added to the end of the Meta Data Info zone.
This Super Block Meta gives the number and offsets of all Super TokenTree Blocks described below
Super Block offset count : 12
Super Block offsets : [528384, 1220608, 1916928, 2609152, 3301376, 3997696, 4689920, 5382144, 6078464, 6770688, 7462912, 7995392]
7) SPARSE Data Block
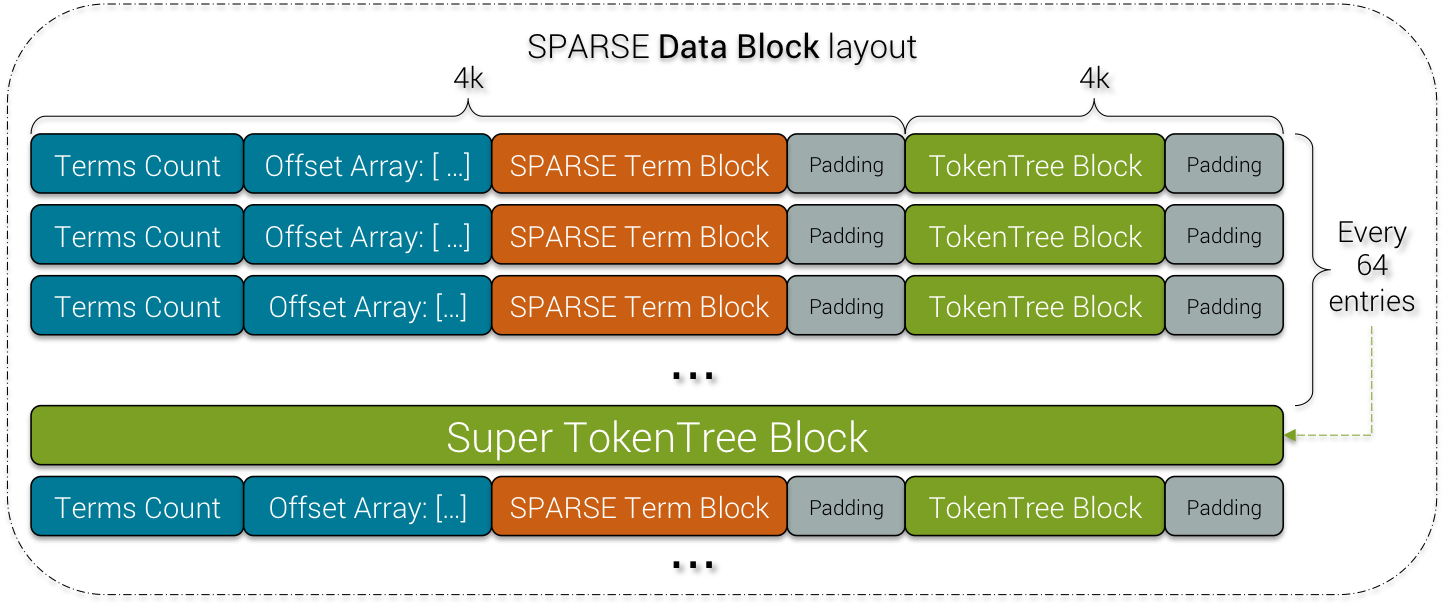
SPARSE Data Block
The SPARSE Data Block contains a SPARSE Term Block (described below) and for each 64 entries, adds an extra Super TokenTree Block. The latter is just a merge of the 64 previous small TokenTree Blocks.
Because it is a SPARSE index, for each indexed value, there is maximum 5 matching rows. Most of the time there is only 1 matching row so indeed the TokenTree Block is very small and contains almost just 1 entry: (token value, offset(s)).
Thus, the Super TokenTree Block is there to aggregate all the (token value, offset(s)) data into one super tree to accelerate queries that cover a wide range of values.
8) SPARSE Term Block
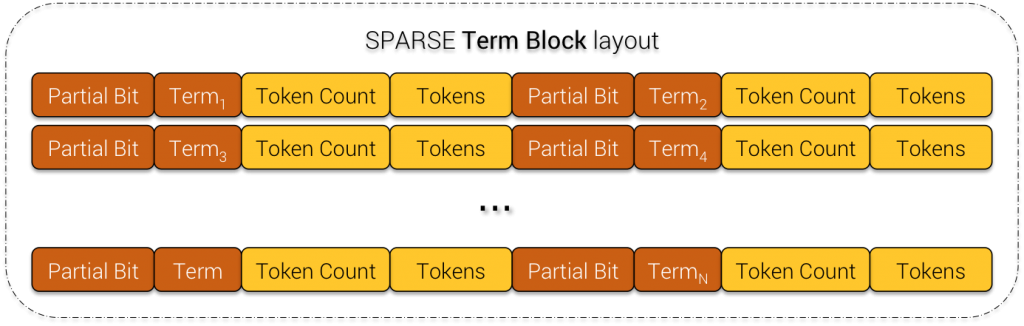
SPARSE Term Block
For SPARSE Term Block, instead of TokenTree offset, SASI just stores token count and an array of token (for the case where there is hash collision).
Term count : 151, Offsets [0, 25, 50, 75, 100, 125, 150, 175, 200, 225, 250, 275, 300, 325, 350, 375, 400, 425, 450, 475, 500, 525, 550, 575, 600, 625, 650, 675, 700, 725, 750, 775, 800, 825, 850, 875, 900, 925, 950, 975, 1000, 1025, 1050, 1075, 1100, 1125, 1150, 1175, 1200, 1225, 1250, 1275, 1300, 1325, 1350, 1375, 1400, 1425, 1450, 1475, 1500, 1525, 1550, 1575, 1600, 1625, 1650, 1675, 1700, 1725, 1750, 1775, 1800, 1825, 1850, 1875, 1900, 1925, 1950, 1975, 2000, 2025, 2050, 2075, 2100, 2125, 2150, 2175, 2200, 2225, 2250, 2275, 2300, 2325, 2350, 2375, 2400, 2425, 2450, 2475, 2500, 2525, 2550, 2575, 2600, 2625, 2650, 2675, 2700, 2725, 2750, 2775, 2800, 2825, 2850, 2875, 2900, 2925, 2950, 2975, 3000, 3025, 3050, 3075, 3100, 3125, 3150, 3175, 3200, 3225, 3250, 3275, 3300, 3325, 3350, 3375, 3400, 3425, 3450, 3475, 3500, 3525, 3550, 3575, 3600, 3625, 3650, 3675, 3700, 3725, 3750]
SPARSE mode Data Term (partial ? false) : 00006d9c-2e82-4121-af62-4985ef049ab2. Token count : 1, Tokens [454478372476719604]
SPARSE mode Data Term (partial ? false) : 0000b112-bd10-4b0f-b630-756d58a120f5. Token count : 1, Tokens [-4566353347737760613]
SPARSE mode Data Term (partial ? false) : 0000c8a7-77a5-4556-aba9-7ae25484e1ac. Token count : 1, Tokens [7930016921529937694]
SPARSE mode Data Term (partial ? false) : 00022bcc-d2c7-43b7-81e0-78e8cea743e6. Token count : 1, Tokens [1669390735346713894]
SPARSE mode Data Term (partial ? false) : 0002aded-efc8-46ea-acb7-56839003eed9. Token count : 1, Tokens [8078947252161450449]
SPARSE mode Data Term (partial ? false) : 0002ffe6-cb63-4055-a3ce-f40a4bc57b46. Token count : 1, Tokens [339460836208023232]
SPARSE mode Data Term (partial ? false) : 0003b80b-3231-447f-a52c-0733cdcb4fc0. Token count : 1, Tokens [-3305941541833453269]
SPARSE mode Data Term (partial ? false) : 000477ab-8965-4d79-9cab-a1257f794eeb. Token count : 1, Tokens [-471202335109983528]
SPARSE mode Data Term (partial ? false) : 0005751e-327c-4c00-8a91-2ff78c41835f. Token count : 1, Tokens [7499979976904876222]
...
9) Pointer Block
Now, we describe how the Pointer Blocks are built and their layout.
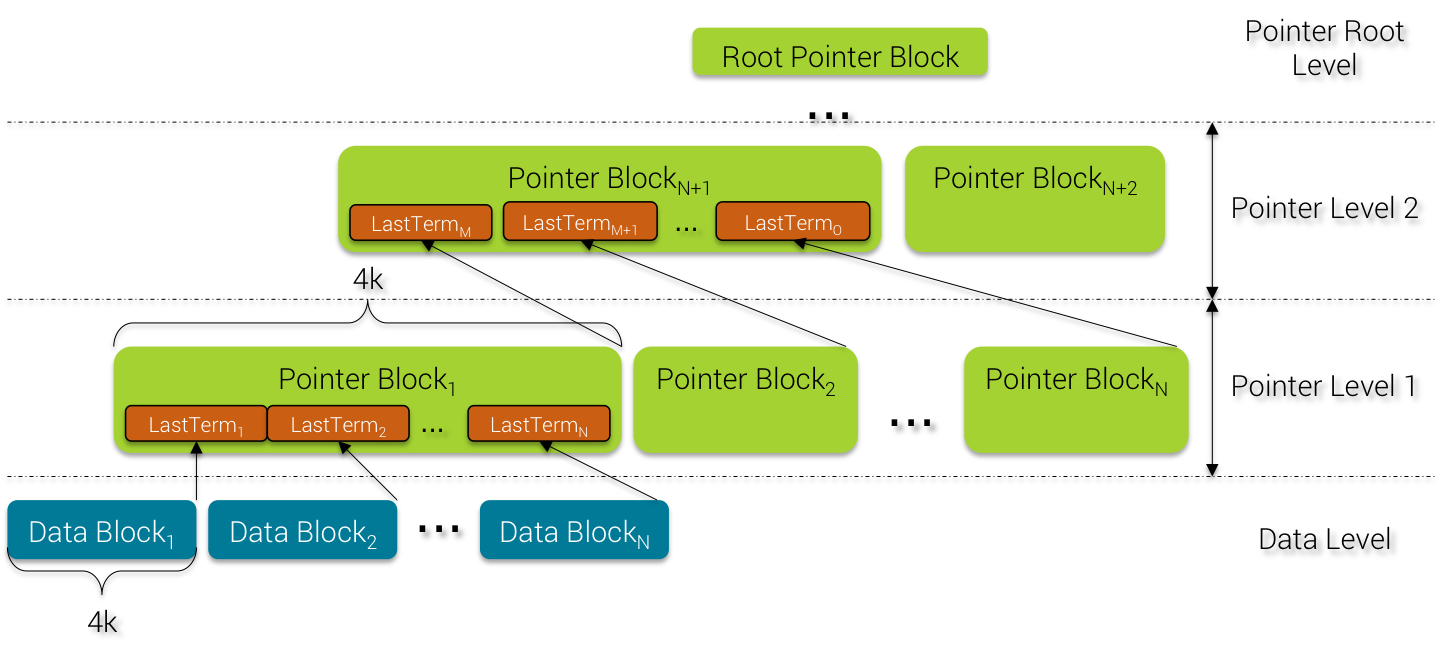
Pointer Block Building
Every time that a Data Block reaches 4k worth of data, it is flushed to disk and the last term is promoted to the upper level called Pointer Level. When this Pointer Block content reaches 4k worth of data again, it is flushed to disk and the last Pointer Term (described below) is promoted to the upper level and so on.
SASI builds the index data from bottom up e.g. first the Data Level and then all the Pointer Levels up to the Root Pointer Level. This bottom-up approach has the advantage not to require a lot of memory because data are flushed to disk for every block of 4k. Inside each Pointer Level, the same 4k worth of data rule applies and this end up by creating a kind of binary tree.
Contrary to classical B+Tree, the Pointer Block tree adds up levels only on 4k block of data threshold so there is no guarantee about tree balance with regard to the content.
Terms are sorted at the Data Level so the terms inside each Pointer Level are also sorted as a result.
Now let's see the structure of each Pointer Block:

Pointer Block
Again, the structure is very similar to a Data Block. The only difference is the Pointer Term Block instead of Term Block.

Pointer Term Block
Inside each Pointer Term Block, each term is pointing to the Data Block Index e.g. the index position of the corresponding Data Block at the Data Level.
This index is useful because SASI stores all the offsets of Data Blocks in an array (accessible by index) in the Data Block Meta we'll see below.
POINTERS BLOCKS
Term count: 7, Offsets [0, 20, 40, 60, 80, 100, 120]
Pointer Term (partial ? false) : fdcff974-bddd-4c4a-a6ff-6615de31d2a1, Block number : 740.
Pointer Term (partial ? false) : fe20819f-393c-483e-9e2f-cbd8193fdd15, Block number : 741.
Pointer Term (partial ? false) : fe722e4d-25c0-49cd-a9b3-914191e36e9c, Block number : 742.
Pointer Term (partial ? false) : fed46ad8-f5a8-406b-a29e-70e71f1862fd, Block number : 743.
Pointer Term (partial ? false) : ff352093-c3e4-4e57-83f5-fb5b9101e3e9, Block number : 744.
Pointer Term (partial ? false) : ff8c2aab-23d4-4b6e-a706-17dda3a78319, Block number : 745.
Pointer Term (partial ? false) : ffeb113c-0bdc-4be5-b3cf-1e0449b37938, Block number : 746.
Term count : 4, Offsets [0, 20, 40, 60]
Pointer Term (partial ? false) : 3f207887-da39-40c0-833c-91547548700f, Block number : 0.
Pointer Term (partial ? false) : 7e6f890a-43a8-4021-a473-f18d575d5466, Block number : 1.
Pointer Term (partial ? false) : be7c4641-d198-4a97-a279-28f54a8e1cc0, Block number : 2.
Pointer Term (partial ? false) : fd711b21-de0c-4270-bb03-956286a2c36a, Block number : 3.
10) Meta Data Info

Meta Data Info
The Meta Data Info block consists of:
- Levels Count: number of Pointer Levels in Pointer Block
- Pointer Block Meta: Pointer Block count and offsets to those blocks
- Data Block Meta: Data Block count and offsets to those blocks
- Super Block Meta (for SPARSE mode only): Super TokenTree Block count and offsets to those blocks
- Level Index Offset: offset from the beginning of the file to the Meta Data Info block

Pointer Block Meta
Levels count : 2
--------------
POINTER BLOCKS META
Block offset count : 1, Block offsets : [37830656]
Block offset count : 2, Block offsets : [22806528, 37826560]

Data Block & Super Block Meta
DATA BLOCKS META
Block offset count : 748, Block offsets : [4096, 12288, 20480, ...]
Super Block offset count : 12, Super Block offsets : [528384, 1220608, 1916928, ...]
It was very hard to reverse-engineer SASI source code to understand the OnDiskIndex layout, even with some help from Pavel Yaskevich. The reason is that the source code is quite abstract (frequent use of generics and polymorphism to mutualise code, which is very good) and very low level (usage of bit operators for performance).
To be able to have a clear understanding of the layout, I had to patch the source code to introduce debugging points through all the life-cycle of OnDiskIndex building and output the content to the file /tmp/debug_SASI.txt. If you want to look into the index structure and see how data are really organized on disk, just apply the SASI Debug Patch. Warning, the patch has been created from Cassandra 3.6-SNAPSPHOT. Future updates to SASI source code may require manual merging when applying this patch.
F) Read Path
1) Query Planner
The integrated Query Planner is the real workhorse of SASI. It is responsible to:
- Create a Query Plan
- Analyze the query
- Build an Expressions tree
- Optimize the Expressions tree with predicates push-down and merge
- Execute the query
First, the query expressions (predicates) are analyzed and grouped into a MultiMap (a map with multiple values). Expressions are sorted by column name and then by operator precedence.
| Operator | Priority (Higher value, Better Prioriry) |
|---|---|
| = | 5 |
| LIKE | 4 |
| >, ≥ | 3 |
| <, ≤ | 2 |
| != | 1 |
| other custom expressions | 0 |
Expressions using LIKE predicate are passed to the analyzer. If the StandardAnalyzer is used, the queried value is tokenized and each token is added as an alternation. A query like WHERE title LIKE 'love sad' will be turned into the equivalent of WHERE title LIKE 'love' OR title LIKE 'sad' (see Operation.analyzeGroup())
The result of the query optimization is an operation tree where predicates are merged and re-arranged.
Let's consider the following query: WHERE age < 100 AND fname = 'p*' AND first_name != 'pa*' AND age > 21
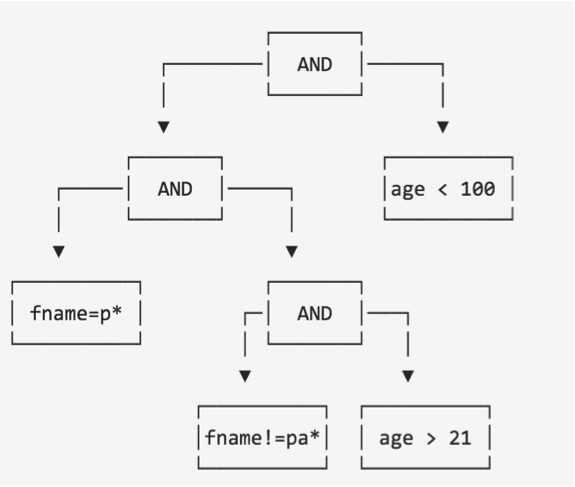
SASI Operation Tree Step 1
Since AND clause is commutative and associative, SASI can merge fname predicate with age predicate.
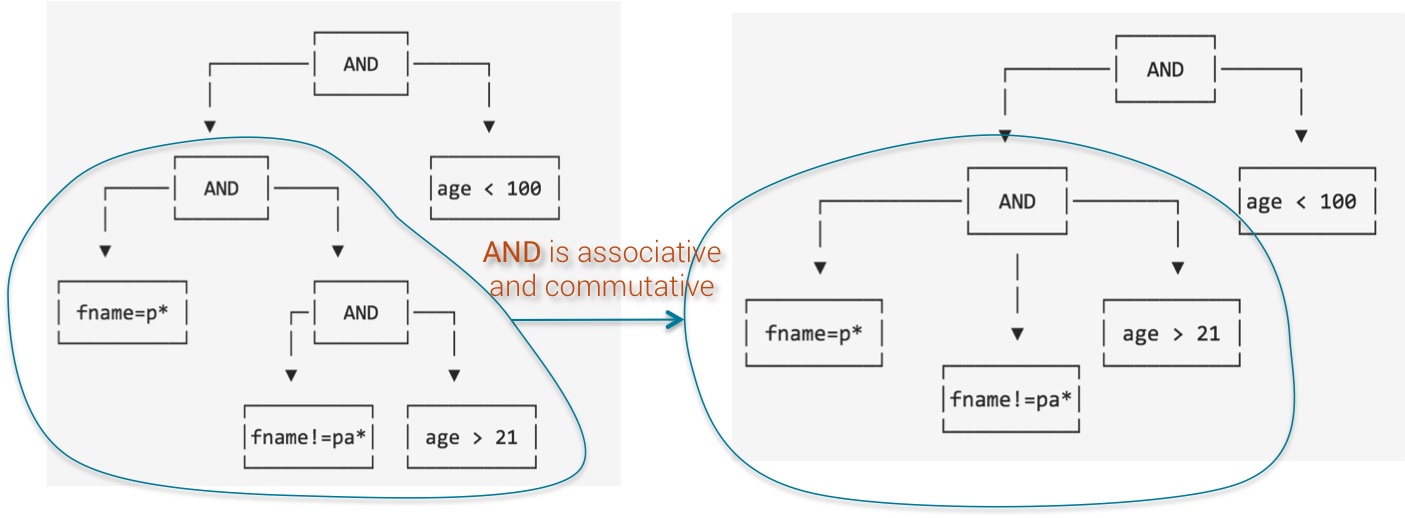
SASI Operation Tree Step 2
Now, not equal operator (!=) can be merged with the prefix search as an exclusion filter.
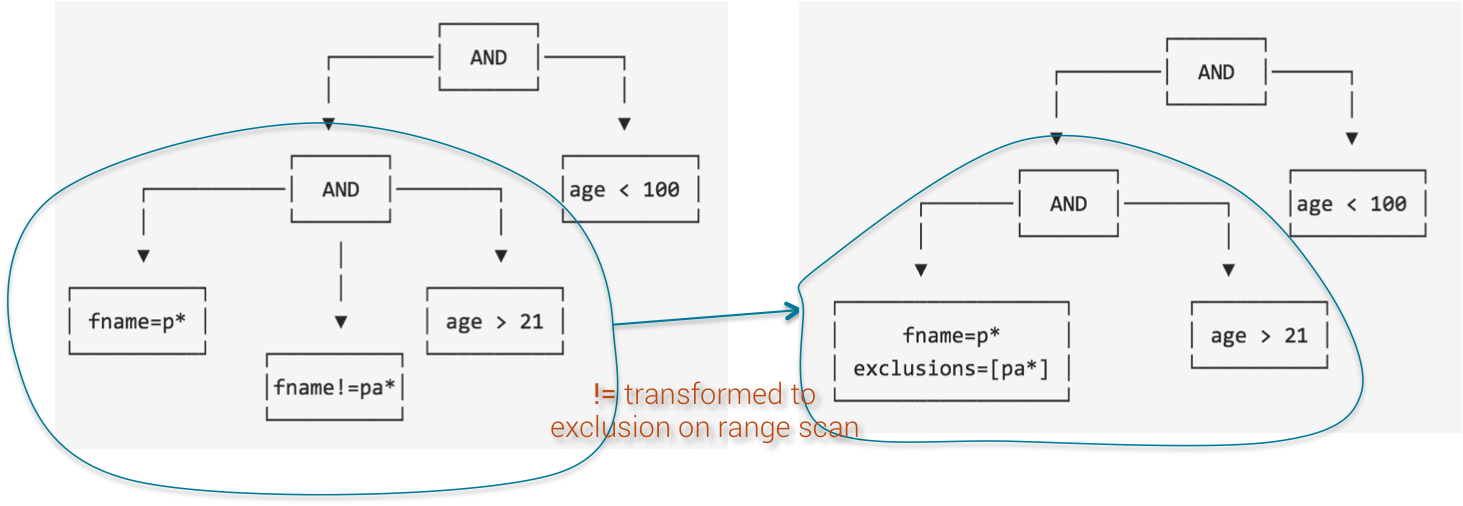
SASI Operation Tree Step 3
Indeed, not equal predicate is implemented internally as range scan (scan on the range of tokens) with exclusion filter. If the query has only a not equal predicate, SASI needs to scan through all the OnDiskIndex file and remove un-wanted values. This is not very optimized but unavoidable.
However, if not equal predicate is used in conjunction with other predicates (LIKE or inequality) then SASI will embed the former as exclusion filter while performing search on the latter.
Finally, the predicates on age can be merged together again because AND is commutative and associative.
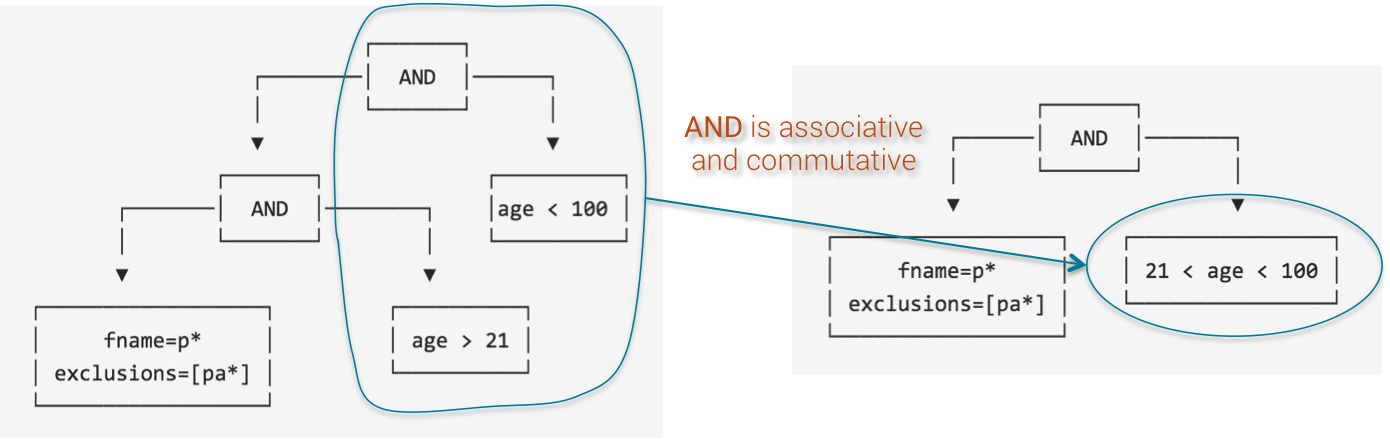
SASI Operation Tree Step 4
2) Cluster Read Path
The read path for SASI query on the cluster is exactly the one implemented for normal range scan query. Please read my article on Native Secondary Index, chapter E) Cluster Read Path to have a clear understanding of how the coordinator issues queries across the cluster.
Because SASIIndex.getEstimatedResultRows() returns Long.MIN_VALUE as a work-around to have higher precedence on native secondary index, the formula to compute the CONCURRENCY_FACTOR for the first round of query is completely ineffective and always return 1.
public long getEstimatedResultRows()
{
// this is temporary (until proper QueryPlan is integrated into Cassandra)
// and allows us to priority SASI indexes if any in the query since they
// are going to be more efficient, to query and intersect, than built-in indexes.
return Long.MIN_VALUE;
}
As a result, every search with SASI currently always hit the same node, which is the node responsible for the first token range on the cluster. Subsequent rounds of query (if any) will spread out to other nodes eventually
Let's hope that this temporary hack will be removed once the Query Plan get fully integrated into Cassandra.
3) Local Read Path
On each local node, SASI will load the OnDiskIndex files into system page cache using memory mapped buffer (org.apache.cassandra.index.sasi.utils.MappedBuffer) to speed up reading and search.
First, on index file opening, SASI reads the last 8 bytes at the end of the file to retrieve the offset (Level Index Offset) of the Meta Data Info block (see data layout above).
Then it loads all the Pointer Block Meta and Data Bloc Meta into memory.
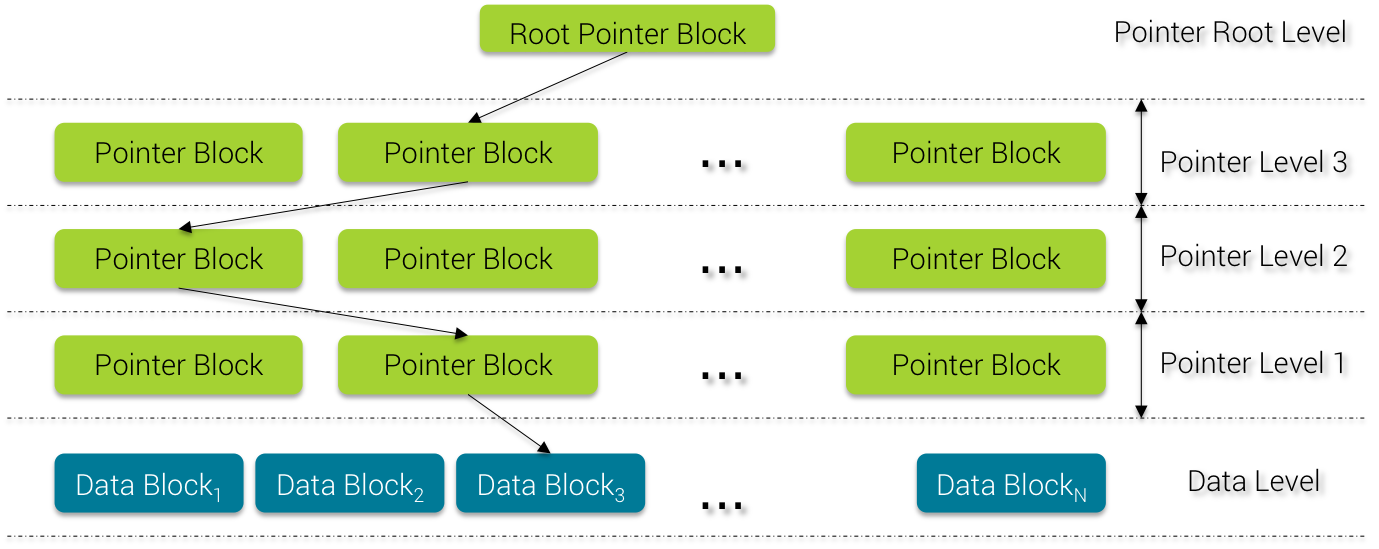
Pointer Block Binary Search
When searching for a term, SASI uses the Pointer Block to perform binary search from the Root Pointer Level down to the last Pointer Level. From this last Pointer Level, SASI knows in which Data Block (because the Pointer Term keeps a reference to the Data Block index) it should look for the actual matched value, if any.
Inside each Data Block, since the terms are sorted, SASI can again use binary search to reach quickly the matching value.
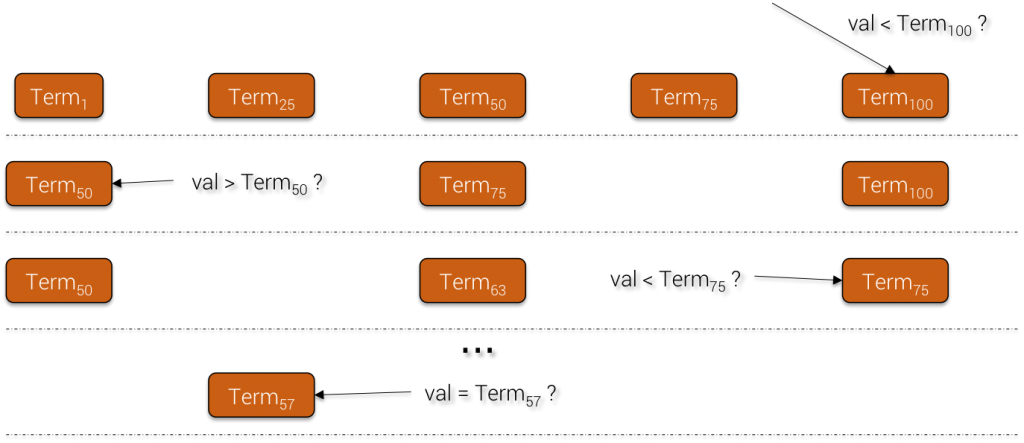
Term Block Binary Search
For prefix search, since all the text terms are stored in their original form, SASI will strip out the % character and compare the searched value with the stored term prefix having the same length as the former.
For example, if the index contains the term 'Jonathan' and the query is LIKE 'John%', SASI will remove the last 4 characters of 'Jonathan' and compare 'Jona' to 'John'. In this case, there is no match.
If the index mode is CONTAINS and the user issues a prefix or equality search, SASI will only use stored terms that have their Partial Bit = false . Indeed, all stored terms whose Partial Bit = true mean that they are a suffix of a longer string and thus cannot be used for neither prefix nor equality search.
Let's illustrate will a simple example. Suppose we index the following names using mode CONTAINS with NonTokenizingAnalyzer: Helen, Johnathan & Patrick:
Data Term (partial ? true) : an. 0x0, TokenTree offset : 0
Data Term (partial ? true) : athan. 0x0, TokenTree offset : 80
Data Term (partial ? true) : atrick. 0x0, TokenTree offset : 160
Data Term (partial ? true) : ck. 0x0, TokenTree offset : 240
Data Term (partial ? true) : elen. 0x0, TokenTree offset : 320
Data Term (partial ? true) : en. 0x0, TokenTree offset : 400
Data Term (partial ? true) : han. 0x0, TokenTree offset : 480
Data Term (partial ? false) : helen. 0x0, TokenTree offset : 560
Data Term (partial ? true) : hnathan. 0x0, TokenTree offset : 640
Data Term (partial ? true) : ick. 0x0, TokenTree offset : 720
Data Term (partial ? false) : johnathan. 0x0, TokenTree offset : 800
Data Term (partial ? true) : k. 0x0, TokenTree offset : 880
Data Term (partial ? true) : len. 0x0, TokenTree offset : 960
Data Term (partial ? true) : n. 0x0, TokenTree offset : 1040
Data Term (partial ? true) : nathan. 0x0, TokenTree offset : 1136
Data Term (partial ? true) : ohnathan. 0x0, TokenTree offset : 1216
Data Term (partial ? false) : patrick. 0x0, TokenTree offset : 1296
Data Term (partial ? true) : rick. 0x0, TokenTree offset : 1376
Data Term (partial ? true) : than. 0x0, TokenTree offset : 1456
Data Term (partial ? true) : trick. 0x0, TokenTree offset : 1536
If we now search by prefix with LIKE 'John%', out of the 20 stored terms, only 3 of them have Partial Bit = false (helen, johnathan & patrick) and will be used for the prefix match.
Once a match is found, SASI returns the token value of the partition and offset(s) from the beginning of the SSTable. This offset will be used by SSTableIndex.DecoratedKeyFetcher.apply() method to retrieve the DecoratedKey from the SSTable. This method is just delegating the work to SSTableReader.keyAt() method.
public DecoratedKey keyAt(long indexPosition) throws IOException
{
DecoratedKey key;
try (FileDataInput in = ifile.createReader(indexPosition))
{
if (in.isEOF())
return null;
key = decorateKey(ByteBufferUtil.readWithShortLength(in));
// hint read path about key location if caching is enabled
// this saves index summary lookup and index file iteration which whould be pretty costly
// especially in presence of promoted column indexes
if (isKeyCacheSetup())
cacheKey(key, rowIndexEntrySerializer.deserialize(in));
}
return key;
}
By chance (or was it intended), calling this method also pulls the entry into the Partition Key Cache so that subsequent access to this partition will leverage the cache to access the partition directly on disk.
Once the DecoratedKey for the matching partition is found, SASI just hands over the data reading part to Cassandra SingleReadCommand which has the responsibility to fetch the matching row(s) and apply reconciliation logic (last-write-win, tombstone ...)
public UnfilteredRowIterator getPartition(DecoratedKey key, ReadExecutionController executionController)
{
if (key == null)
throw new NullPointerException();
try
{
SinglePartitionReadCommand partition = SinglePartitionReadCommand.create(command.isForThrift(),
cfs.metadata,
command.nowInSec(),
command.columnFilter(),
command.rowFilter().withoutExpressions(),
DataLimits.NONE,
key,
command.clusteringIndexFilter(key));
return partition.queryMemtableAndDisk(cfs, executionController.baseReadOpOrderGroup());
}
finally
{
checkpoint();
}
}
At that point the alert reader should realise that SASI does not fully optimize SSTable disk access. Indeed the index only stores the offset to the complete partition, not to the exact matching rows. If your schema has very wide partitions, Cassandra will have to full scan it to find the rows. Worst, unlike native secondary index where clustering values are also kept in the index data to help skipping blocks to the nearest position, SASI index only provides partition offsets.
I asked Pavel Yaskevich why SASI team did not optimize further the read path. It turns out that they thought about it but decided intentionally to keep the current design.
Indeed, to improve the read path, we could store the offset to the row itself instead of the partition. But problem is currently in the Cassandra SSTable code infrastructure, it is not possible to pass offset to access a row directly. And it would require substantial changes, at least, to introduce row offset.
The second idea is to store clustering columns values in the OnDiskIndex to help skipping blocks of data. But again it would require storing more extra data in the index file and make the read path more complex.
Anyway the current read path is not very fast for linear scanning over a huge amount of data, thus the JIRA epic CASSANDRA-9259 is opened to improve it and once done, SASI can naturally benefit from the performance improvement.
G) Disk Space Usage
To be able to search with suffix, SASI has to compute all combinations of suffix from the original term so the longer the term, the more there are suffixes to be stored. The number of suffix is equal to term_size - 1.
As a mean of comparison, I have a table albums with the following schema:
CREATE TABLE music.albums (
id uuid PRIMARY KEY,
artist text,
country text,
quality text,
status text,
title text,
year int
)
The table contains ≈ 110 000 albums and the SSTable size on disk is about 6.8Mb. I created some indices on this table. Below is an overview of the disk space usage for each index:
| Index Name | Index Mode | Analyzer | Index Size | Index Size/SSTable Size Ratio |
|---|---|---|---|---|
| albums_country_idx | PREFIX | NonTokenizingAnalyzer |
2Mb | 0.29 |
| albums_year_idx | PREFIX | N/A | 2.3Mb | 0.34 |
| albums_artist_idx | CONTAINS | NonTokenizingAnalyzer |
30Mb | 4.41 |
| albums_title_idx | CONTAINS | StandardAnalyzer |
41Mb | 6.03 |
As we can see, using CONTAINS mode can increase the disk usage by x4 - x6. Since album titles tends to be a long text, the inflation rate is x6. It will be more if we chose the NonTokenizingAnalyzer because the StandardAnalyzer splits the text into tokens, remove stop words and perform stemming. All this help reducing the total size of the term.
As a conclusion, use CONTAINS mode wisely and be ready to pay the price in term of disk space. There is no way to avoid it. Even with efficient search engines like ElasticSearch or Solr, it is officially recommended to avoid substring search (LIKE %substring%) for the sake of performance.
H) Some Performance Benchmarks
Below are the hardware specs used for the benchmark:
- 13 bare metal machines
- 6 CPU (HT) = 12 cores
- 64Gb RAM
- 4 SSD RAID 0 for a total of 1.5Tb
Cassandra configuration:
- num token: 64
- concurrent_compactors: 2
- compaction_throughput_mb_per_sec: 256
- G1 GC with 32Gb heap
Schema:
CREATE KEYSPACE test WITH replication = {'class': 'NetworkTopologyStrategy', 'datacenter1': '2'} AND durable_writes = true;
create table if not exists test.resource_bench (
dsr_id uuid,
rel_seq bigint,
seq bigint,
dsp_code varchar,
model_code varchar,
media_code varchar,
transfer_code varchar,
commercial_offer_code varchar,
territory_code varchar,
period_end_month_int int,
authorized_societies_txt text,
rel_type text,
status text,
dsp_release_code text,
title text,
contributors_name list<text>,
unic_work text,
paying_net_qty bigint,
PRIMARY KEY ((dsr_id, rel_seq), seq)
) WITH CLUSTERING ORDER BY (seq ASC)
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'};
CREATE CUSTOM INDEX resource_period_end_month_int_idx ON sharon.resource_bench (period_end_month_int) USING 'org.apache.cassandra.index.sasi.SASIIndex' WITH OPTIONS = {'mode': 'PREFIX'};
CREATE CUSTOM INDEX resource_territory_code_idx ON sharon.resource_bench (territory_code) USING 'org.apache.cassandra.index.sasi.SASIIndex' WITH OPTIONS = {'analyzer_class': 'org.apache.cassandra.index.sasi.analyzer.NonTokenizingAnalyzer', 'case_sensitive': 'false'};
CREATE CUSTOM INDEX resource_dsp_code_idx ON sharon.resource_bench (dsp_code) USING 'org.apache.cassandra.index.sasi.SASIIndex' WITH OPTIONS = {'analyzer_class': 'org.apache.cassandra.index.sasi.analyzer.NonTokenizingAnalyzer', 'case_sensitive': 'false'};
The table has 1 numerical DENSE index (resource_period_end_month_int_idx) and 2 text DENSE indices (resource_territory_code_idx & resource_dsp_code_idx).
The cardinality for each indexed columns are:
period_end_month_int: 36 distinct valuesterritory_code: 7 distinct valuesdsp_code: 7 distinct values
Then I deployed a co-located Spark installation on those machines and used a Spark script to inject 1.3 billion rows.
Without SASI index, the insert took ≈ 4h. With the above 3 indices, it took ≈ 6h. Clearly the index has an impact on the write and compaction throughput because of the overhead required to create and flush the index files.
I also benchmarked the time it took to build SASI index from existing data:
period_end_month_int: 1h20territory_code: 1hmodel_code: (DENSE text index with only 2 distinc values): 1h34
Next, I benchmarked the query latency. There are 2 distinct scenarios. First I used server-side paging to fetch all data matching some predicates. The second test adds a LIMIT clause with different value to see how it can impact response time.
Please note that when LIMIT is not set, fetchSize = 10000 and a sleep time of 20 ms for each page is used to let the cluster breath.
| Query | Limit | Fetched Rows | Query Time |
|---|---|---|---|
WHERE period_end_month_int=201401 |
None | 36 109 986 | 609 secs |
WHERE period_end_month_int=201406 AND dsp_code='vevo' |
None | 2 781 492 | 330 secs |
WHERE period_end_month_int=201406 AND dsp_code='vevo' AND territory_code='FR' |
None | 1 044 547 | 372 secs |
WHERE period_end_month_int=201406 AND dsp_code='vevo' |
None | 360 334 | 116 secs |
WHERE period_end_month_int=201406 |
100 | 100 | 26 ms |
WHERE period_end_month_int=201406 |
1000 | 1000 | 143 ms |
WHERE period_end_month_int=201406 |
10000 | 10000 | 693 ms |
WHERE period_end_month_int=201406 |
100000 | 100000 | 5087 ms |
WHERE period_end_month_int=201406 AND dsp_code='vevo' |
100 | 100 | 35 ms |
WHERE period_end_month_int=201406 AND dsp_code='vevo' |
1000 | 1000 | 175 ms |
WHERE period_end_month_int=201406 AND dsp_code='vevo' |
10000 | 10000 | 1375 ms |
WHERE period_end_month_int=201406 AND dsp_code='vevo' |
100000 | 100000 | 16984 ms |
WHERE period_end_month_int=201406 AND dsp_code='vevo' AND territory_code='FR' |
100 | 100 | 71 ms |
WHERE period_end_month_int=201406 AND dsp_code='vevo' AND territory_code='FR' |
1000 | 1000 | 337 ms |
WHERE period_end_month_int=201406 AND dsp_code='vevo' AND territory_code='FR' |
10000 | 10000 | 4548 ms |
WHERE period_end_month_int=201406 AND dsp_code='vevo' AND territory_code='FR' |
100000 | 100000 | 8658 ms |
WHERE period_end_month_int=201406 AND dsp_code='vevo' |
100 | 100 | 378 ms |
WHERE period_end_month_int=201406 AND dsp_code='vevo' |
1000 | 1000 | 2952 ms |
WHERE period_end_month_int=201406 AND dsp_code='vevo' |
10000 | 10000 | 5026 ms |
WHERE period_end_month_int=201406 AND dsp_code='vevo' |
100000 | 100000 | 16319 ms |
The results are quite interesting. When fetching all the data out of Cassandra using server-side paging, the more predicates we have to narrow down the result set, the faster it is because there are less rows to retrieve, which is quite intuitive.
However, results of queries using LIMIT is more surprising. For small values of limit, we can see that the more we add predicates and the slower the query is ... until some threshold (around 10 000 rows) where the latency look more similar to server-side paging queries.
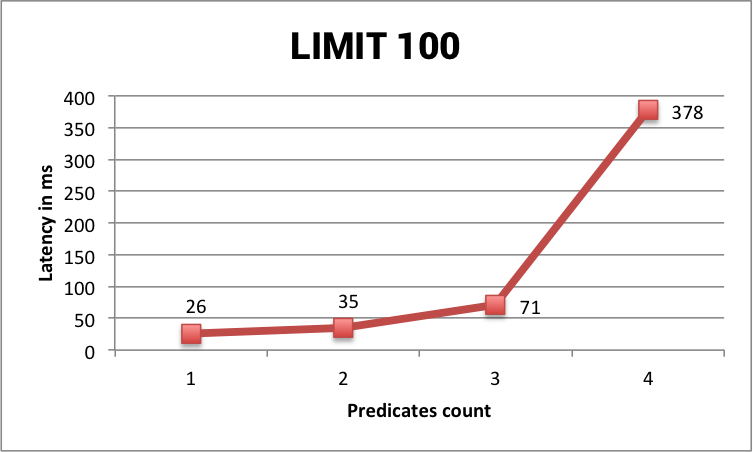
Benchmark Limit 100
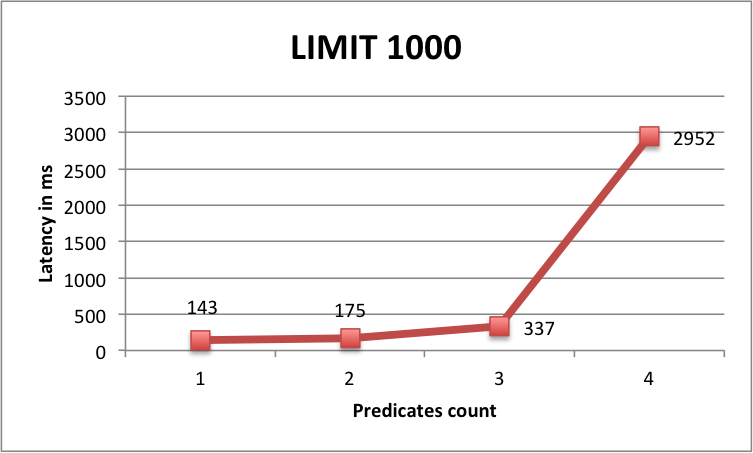
Benchmark Limit 1000
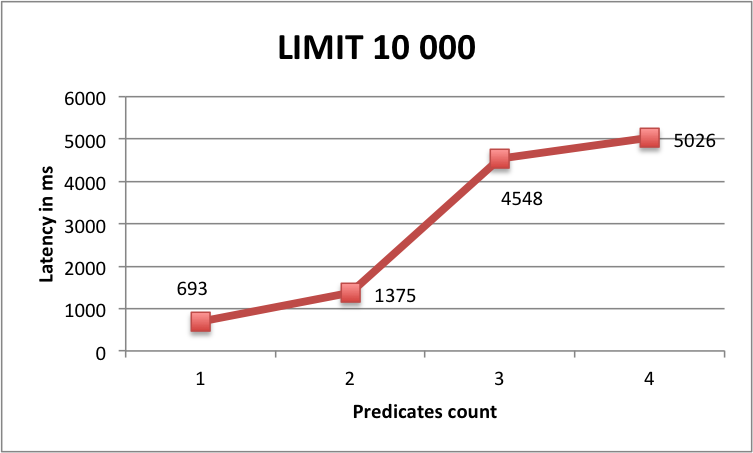
Benchmark Limit 10000
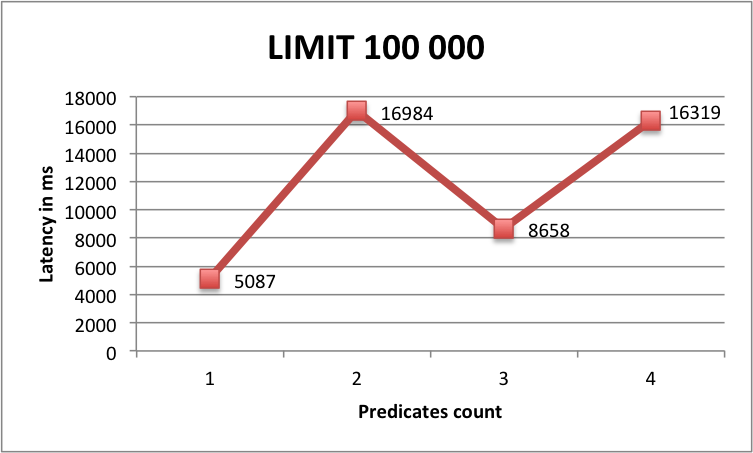
Benchmark Limit 100000
One possible explanation is that the more predicates you add and the more index files SASI has to read for the query so for small LIMIT values it spends more time on index reading than on fetching raw data from Cassandra. But above a LIMIT threshold, adding more predicates is beneficial because you reduce the number of returned rows thus limit Cassandra sequential scans.
Generally speaking, there is a limit of number of returned rows above which it is slower to query using SASI or any secondary index compared to a full table scan using ALLOW FILTERING and paging. Why is that ? Because reading the index files into memory has a cost and this cost only increases when the returned result set grows.
I) SASI vs Search Engines
Somehow one wants to compare SASI with classical search engines like ElasticSearch, Solr or Datastax Enterprise Search. The comparison is quite simple indeed. Despite its convenience and the fact that SASI is strongly integrated to Cassandra and CQL, it has a number of drawbacks when compared to real search engines.
- SASI requires 2 passes on disk to fetch data: 1 pass to read the index files and 1 pass for the normal Cassandra read path whereas search engines retrieves the result in a single pass (DSE Search has a singlePass option too). By laws of physics, SASI will always be slower, even if we improve the sequential read path in Cassandra
- Although SASI allows full text search with tokenization and CONTAINS mode, there is no scoring applied to matched terms
- SASI returns result in token range order, which can be considered as random order from the user point of view. It is not possible to ask for total ordering of the result, even when LIMIT clause is used. Search engines don't have this limitation
- last but not least, it is not possible to perform aggregation (or faceting) with SASI. The GROUP BY clause may be introduced into CQL in a near future but it is done on Cassandra side, there is no pre-aggregation possible on SASI terms that can help speeding up aggregation queries
That being said, if you don't need ordering, grouping or scoring, SASI is a very nice alternative to pulling a search engine into the game.
I would never have though that I could one day use the LIKE '%term%' predicate with Cassandra so from this point of view it is already a great improvement over the limitations of the past.
J) SASI Trade-Offs
You should use SASI if:
- you need multi criteria search and you don't need ordering/grouping/scoring
- you mostly need 100 to 1000 of rows for your search queries
- you always know the partition keys of the rows to be searched for (this one applies to native secondary index too)
- you want to index static columns (SASI has no penalty since it indexes the whole partition)
You should avoid SASI if:
- you have very wide partitions to index, SASI only give the partition offset. The expensive linear scanning is still performed on Cassandra side, without the help of clustering column index for skipping blocks
- you have strong SLA on search latency, for example sub-second requirement
- you need search for analytics scenarios (SASI is not the right fit to fetch half of your table) unless you use SASI with co-located Apache Spark but even in this case, search engines win with 2 orders of magnitude for latency
- ordering of the search results is important for you
If you decide to try SASI in production, please keep in mind that SASI does impact your write/flush throughput, compaction throughput as well as repair and streaming operations. It is quite expected because SASI index files follow SSTable life-cycle.
Also beware of the CONTAINS mode whose cost of disk space can be prohibitive.
Avoid using (!=) alone because it will end up scanning entire token ranges, which is expensive. Use it in combination with other predicates.
This is a most excellent post. Succinct and easy to understand. For some one who has just started using Cassandra (3 days ago) this is a great reference .
Thanks
A great post. Just a tiny note, I think it worth mentioning on what version of Cassandra SASI index were introduced. Maybe the casual reader could not be aware of this information.
Good remark, I just update the post. Recommendation is to use at least Cassandra 3.5
For this query “WHERE period_end_month_int=201406 AND dsp_code=’vevo’
AND territory_code=’FR’ AND model_code=’AdFunded'” , I got the following error.
“com.datastax.driver.core.exceptions.InvalidQueryException: Cannot execute this query as it might involve data filtering and thus may have unpredictable performance. If you want to execute this query despite the performance unpredictability, use ALLOW FILTERING”
I don’t want to do “ALLOW FILTERING”. Any suggestions? Thanks
ALLOW FILTERING is MANDATORY if you use more than 1 SASI index in the WHERE clause
However, it’s just a syntax rule, in term of performance you don’t suffer full scan like with native secondary index
I have enable trace on a query with 2 SASI indexes and allow filtering and it looks similar with when using Allow Filtering and 2 native secondary indexes = the index with highest selectivity is filtered and the second on is executed in coordinator memory. How can we be sure that actually both indexes are filtered on the nodes. Cassandra documentation specifies that “If ALLOW FILTERING is used, SASI also supports queries with multiple predicates using AND. With SASI, the performance pitfalls of using filtering are not realized because the filtering is not performed even if ALLOW FILTERING is used.”. From what I see in the traces though one index is executed and the second one is filtered locally in the coordinator.
Humm it would be a bug, can you provide your schema (+ the CREATE CUSTOM INDEX statements) as well as the SELECT that uses 2 indices ?
Hi, I have two questions:
1. if the “TokenTreeBlock” is a B-tree, why I do not find the relationship between nodes (i.e., parent and its children) in the detailed format in this article?
2. Why sparse index has the limitation of 5 (i.e., less than 5 rows matched)? I feel confusing because B-tree has no such limitation… Besides, if so, how to index a float/double formatted column (with many different values and cannot be sure that each value only appears in less than 5 rows) by SASI, which kind of index is suitable?
Many Thanks~!
1) Read the content of “Example of TokenTree block content (1 Root/Leaf node + 1 Root node with 3 Leaf nodes)”. You can see that the Root Metadata has offsets to child leaves
2) I don’t know why the original implementation sets the limitation to 5. The number 5 looks like some arbitrary limit. If you’re not sure that your index will have less than 5 matching rows, then use default PREFIX mode …
Excellent post and very detailed explanation. You should propose a pull request to improve the driver documentations…
Hallo Doan,
Can you please explain what it means that SASII Sparse index should contain less than 5 keys per indexed value? What if I have more than 5 records per indexed value? Will the Sparse index still work? What will be the performance?
Thank you!
The number 5 is quite arbitrary I agree. It comes from the original implementation of SASI at Apple.
Hmmmm… I currently run a query with an int indexed with sasii sparse which returns 44 results without a problem. All 44 results have the same value for the int indexed with sasii sparse. No error is thrown…
Can I trust that the 5 records limit will not be a problem?
Dear Doan,
Can you please comment? I am currently retrieving over 300 records all indexed with sasii sparse on the same integer value without a problem. Can I trust that the limit of 5 records per indexed value is not going to lead to errors?
The source code is your friend. It’s an open source projet so you’re free to go and check. The information in this blog post is more than 1 year old so maybe the source code and the limitation of max 5 distincts values has been removed
Hi Doan,
I have a requirement where select query is using the partition key, a boolean (which I have made as secondary index), a timestamp (for which I am using SASI Index – SPARSE). I cannot have the boolean and timestamp as part of primary key.
Select query gives this error
Traceback (most recent call last):
File “/usr/local/bin/cqlsh”, line 1243, in perform_simple_statement
result = future.result()
File “cassandra/cluster.py”, line 3982, in cassandra.cluster.ResponseFuture.result
raise self._final_exception
ReadFailure: Error from server: code=1300 [Replica(s) failed to execute read] message=”Operation failed – received 0 responses and 1 failures” info={‘failures’: 1, ‘received_responses’: 0, ‘required_responses’: 1, ‘consistency’: ‘ONE’}
Query using two secondary indices or two SASI indices work fine. Only when I combine a secondary index with a SASI index this issue comes. Can you please help me to fix it.
Also when I dont index the boolean field, query just has the SASI index on timestamp which works. Will this be slower ?
Thanks
Bala
The solution is to use SASI for both boolean and timestamp index and forget about the native secondary index
Thanks Doan. That makes a lot of sense. For boolean which mode can I use. PREFIX, CONTAINS, or SPARSE seems to be not a good fit for boolean.
We are facing some issues while using casssandra along with SASI index. we are not getting the expected results. we have replication factor 3 and we query with consistency Quorum and the SASI index is created few days back and it was working fine. But we are facing some issues as the data grows and when the records are getting modified frequently.
we are getting the data when the SASI index is not used,
datastore@cqlsh:stats_cache> SELECT created_at, modified_at from cache where query_path = ‘user_trips’ and query_string = ‘{“date”: “31-01-2018”, “trip_id”: “1499”}’ limit 1000;
created_at | modified_at
———————————+———————————
2018-02-02 15:38:55.437000+0000 | 2018-02-02 19:22:16.796000+0000
But when we query using the SASI index we are not getting any results. we are facing this issues for the particular trip_id
datastore@cqlsh:stats_cache> SELECT created_at, modified_at from cache where query_path = ‘user_trips’ and query_string = ‘{“date”: “31-01-2018”, “trip_id”: “1499”}’ and created_at > ‘2018-02-02 10:03:54’ limit 1000;
query_string | query_path | created_at | modified_at | response
————–+————+————+————-+———-
(0 rows)
datastore@cqlsh:stats_cache> SELECT created_at, modified_at from cache where query_path = ‘user_trips’ and query_string = ‘{“date”: “31-01-2018”, “trip_id”: “1499”}’ and created_at > ‘2017-02-02 17:03:54’ limit 1000;
query_string | query_path | created_at | modified_at | response
————–+————+————+————-+———-
(0 rows)
datastore@cqlsh:stats_cache> SELECT created_at, modified_at from cache where query_path = ‘user_trips’ and query_string = ‘{“date”: “31-01-2018”, “trip_id”: “1499”}’ and created_at > 0 ;
query_string | query_path | created_at | modified_at | response
————–+————+————+————-+———-
(0 rows)
datastore@cqlsh:stats_cache> SELECT created_at, modified_at from cache where query_path = ‘user_trips’ and query_string = ‘{“date”: “31-01-2018”, “trip_id”: “1499”}’ and created_at > 0 ;
query_string | query_path | created_at | modified_at | response
————–+————+————+————-+———-
(0 rows)
datastore@cqlsh:stats_cache> SELECT created_at, modified_at from cache where query_path = ‘user_trips’ and query_string = ‘{“date”: “31-01-2018”, “trip_id”: “1499”}’ and created_at > 0 ;
query_string | query_path | created_at | modified_at | response
————–+————+————+————-+———-
(0 rows)
datastore@cqlsh:stats_cache> SELECT created_at, modified_at from cache where query_path = ‘user_trips’ and query_string = ‘{“date”: “31-01-2018”, “trip_id”: “1499”}’ and created_at > 0 ;
query_string | query_path | created_at | modified_at | response
————–+————+————+————-+———-
Table spec and config used,
datastore@cqlsh> CONSISTENCY QUORUM;
Consistency level set to QUORUM.
datastore@cqlsh> CONSISTENCY
Current consistency level is QUORUM.
Desc of the Keyspace
CREATE KEYSPACE cs1_cache WITH replication = {‘class’: ‘SimpleStrategy’, ‘replication_factor’: ‘3’} AND durable_writes = true;
Table Spec,
CREATE TABLE stats_cache.cache (
query_string text,
query_path text,
created_at timestamp,
modified_at timestamp,
response text,
PRIMARY KEY (query_string, query_path)
) WITH CLUSTERING ORDER BY (query_path ASC)
AND bloom_filter_fp_chance = 0.01
AND caching = {‘keys’: ‘ALL’, ‘rows_per_partition’: ‘NONE’}
AND comment = ”
AND compaction = {‘class’: ‘org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy’, ‘max_threshold’: ’32’, ‘min_threshold’: ‘4’}
AND compression = {‘chunk_length_in_kb’: ’64’, ‘class’: ‘org.apache.cassandra.io.compress.LZ4Compressor’}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 86400
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = ’99PERCENTILE’;
CREATE CUSTOM INDEX cache_created_at_idx ON stats_cache.cache (created_at) USING ‘org.apache.cassandra.index.sasi.SASIIndex’ WITH OPTIONS = {‘mode’: ‘SPARSE’};
CREATE CUSTOM INDEX cache_modified_at_idx ON stats_cache.cache (modified_at) USING ‘org.apache.cassandra.index.sasi.SASIIndex’ WITH OPTIONS = {‘mode’: ‘SPARSE’};
Do we need to do any configuration changes ?
Check your date syntax (created_at > ‘2017-02-02 17:03:54’ ). CQL is very picky with regards to date format
Thanks for the quick reply.
we started using epoc time format , i.e (created_at > 0 (some time in millis)) and even after using it we did not get any results.
This happens only for few trip ids, for the other trip ids the same query is working fine.
For the trips with issues the select is working fine only after the next update, even created_at > 0 was not working till the row is updated/inserted again.
This issues happens rarely and most of the time the reads are successful . Will there be any issue if the write qps is very high ?
Now we are using epoc time in millis and our read qps is 100 and we have 3000 write qps and this issue happens rarely i.e once or twice in a minute.
we are facing this in production, please help.
java.io.IOException: Term – ‘xxx’ belongs to more than 5 keys in SPARSE mode, which is not allowed.
org.apache.cassandra.io.FSWriteError: java.io.IOException: Term – ‘2018-02-02 19:50Z’ belongs to more than 5 keys in SPARSE mode, which is not allowed
I think we are having more than 5 values in same date time as we are having very high write qps, so the cache creation for some entries is missing. Should we use “mode” : Prefix instead of Sparse
That’s the root cause. Drop and recreate the index with PREFIX mode
Thanks a lot for the help, we will try and let you know. One more confusion , for the Boolean what mode should we use . PREFIX, CONTAINS, or SPARSE ?
Hello doanduyhai,
Recently i saw below errors on few of my nodes during a repair. Do you know what this means?
ERROR [SASI-General:520] 2018-06-25 18:30:13,054 PerSSTableIndexWriter.java:266 – Failed to build index segment /data4/cassandra/data/wss_ear/m_row_keys_m-616dc52044ea11e8892779a9bfafe78c/mc-36714-big-SI_m_row_keys_m_mv_status_idx.db
ERROR [SASI-General:520] 2018-06-25 18:30:13,057 PerSSTableIndexWriter.java:266 – Failed to build index segment /data4/cassandra/data/wss_ear/m_row_keys_m-616dc52044ea11e8892779a9bfafe78c/mc-36714-big-SI_m_row_keys_m_uc_status_idx.db
ERROR [SASI-General:520] 2018-06-25 18:30:13,069 PerSSTableIndexWriter.java:266 – Failed to build index segment /data4/cassandra/data/wss_ear/m_row_keys_m-616dc52044ea11e8892779a9bfafe78c/mc-36714-big-SI_m_row_keys_m_rowkey_idx.db
ERROR [CompactionExecutor:4356] 2018-06-25 18:30:13,167 DataTracker.java:149 – Can’t open index file at /data4/cassandra/data/wss_ear/m_row_keys_m-616dc52044ea11e8892779a9bfafe78c/mc-36714-big-SI_m_row_keys_m_mv_status_idx.db, skipping.
ERROR [CompactionExecutor:4356] 2018-06-25 18:30:13,167 DataTracker.java:149 – Can’t open index file at /data4/cassandra/data/wss_ear/m_row_keys_m-616dc52044ea11e8892779a9bfafe78c/mc-36714-big-SI_m_row_keys_m_rowkey_idx.db, skipping.
ERROR [CompactionExecutor:4356] 2018-06-25 18:30:13,170 DataTracker.java:149 – Can’t open index file at /data4/cassandra/data/wss_ear/m_row_keys_m-616dc52044ea11e8892779a9bfafe78c/mc-36714-big-SI_m_row_keys_m_uc_status_idx.db, skipping.
ERROR [Reference-Reaper:1] 2018-06-25 18:30:42,485 Ref.java:224 – LEAK DETECTED: a reference (org.apache.cassandra.utils.concurrent.Ref$State@79b3f292) to class org.apache.cassandra.io.sstable.format.SSTableReader$InstanceTidier@1756766536:/data4/cassandra/data/wss_ear/m_row_keys_m-616dc52044ea11e8892779a9bfafe78c/mc-36714-big was not released before the reference was garbage collected
ERROR [Reference-Reaper:1] 2018-06-25 18:30:42,485 Ref.java:224 – LEAK DETECTED: a reference (org.apache.cassandra.utils.concurrent.Ref$State@3f0f3685) to class org.apache.cassandra.io.sstable.format.SSTableReader$InstanceTidier@1756766536:/data4/cassandra/data/wss_ear/m_row_keys_m-616dc52044ea11e8892779a9bfafe78c/mc-36714-big was not released before the reference was garbage collected
ERROR [Reference-Reaper:1] 2018-06-25 18:30:42,485 Ref.java:224 – LEAK DETECTED: a reference (org.apache.cassandra.utils.concurrent.Ref$State@73c46d2c) to class org.apache.cassandra.io.sstable.format.SSTableReader$InstanceTidier@1756766536:/data4/cassandra/data/wss_ear/m_row_keys_m-616dc52044ea11e8892779a9bfafe78c/mc-36714-big was not released before the reference was garbage collected
Look like you have some corruption. Without further data, I would recommend to drop and recreate the index. WARNING: on a huge table (like 1Tb of data) it may be very time and resource consuming so don’t take the decision to recreate the index lightly
Thanks for replying doanduyhai. My table is a tiny one, its around few Mb’s only. Do you think nodetool rebuild index works instead of dropping and recreating the index?
Yes, you can use nodetool rebuild_index as well
hello Hai,
We are facing some issues while using casssandra along with SASI index
could you help us on this issue .here is the log
java.lang.ClassCastException: org.apache.cassandra.index.
> internal.composites.RegularColumnIndex cannot be cast to
> org.apache.cassandra.index.sasi.SASIIndex
Hello doanduyhai,
Just curious, why not data block just store partition offset instead of token so we can get rid of Common TokenTree? Is it because of the slim chance of that token hash collision? If this is the case maybe there will be better solution than having a extra component? And it’s indeed seems much more reasonable if we are storing row offset, is changing SASL to storing row offset on the schedule?
Yes I guess the reason to store token is because of possible (but very rare) hash collision
About storing row offset in SASI, an attempt has been made a few year back but the changes have been rollbacks because of lots of regression. Indeed when dealing with low level impl like this SASI index, it’s pretty hard. Since then no body has ever touched the code of SASI. There is even a desire among Cassandra committer to remove SASI. Right now SASI is flagged as experimental in Cassandra, pretty sad